
The best part about security research is the myriad of ways you can find bugs. Sometimes bugs present themselves through diligent research and planning over decades, some bugs demand deep thinking and well-positioned tools, and other times you throw your water bottle at the keyboard and something unexpected happens. Finding the buffer overflow vulnerability in md2roff version 1.7 was somewhat of a combination of these tactics.
Even though buffer overflows are slowly dwindling due to compiler and CPU enhancements, they are still very common in programs written in C and C++. In this post, we are going to step through the process of how I discovered a buffer overflow zero-day in the md2roff tool using AFL++ (American Fuzzy Lop).
Prerequisites
- Basic C Programming and Compilation
- Basic Linux Command Line Tools
- Basic Understanding of Buffer Overflows
- Basic Understanding of the Stack and Heap
- Basic Understanding of Fuzzers
Disclosure and Disclaimer
The buffer overflow vulnerability was responsibly disclosed to the md2roff security team. This post was intended for developers who are interested in keeping their applications secure and is for EDUCATIONAL PURPOSES ONLY. I do not condone illegal activity and cannot be held responsible for the misuse of this information.
AFL++
Let’s start with a brief introduction on AFL++. At its core, AFL++ is a fuzzer that generates (mostly) random input based on an initial test case given to it by a user. The randomly generated input is subsequently fed into a target software program. As AFL++ learns more about the program, it mutates the input to better identify bugs with the goal of crashing the program by making it exhibit unexpected behavior. I would highly recommend checking out their Github for more details on exactly how this works. The entire process from compiling a target using AFL++ instrumentation to inciting a crash can be seen below:
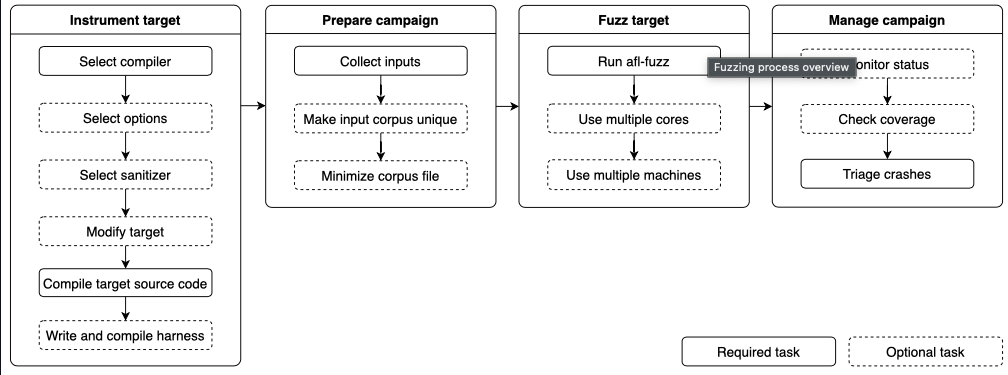
AFL++ is the successor to AFL, which was originally developed by Michał Zalewski at Google. This quick overview is quite an oversimplification of what AFL++ does. The important bits of information required to get started with AFL++ are compilation using instrumentation, creating inputs, fuzzing the program, and triaging crashes.

If you are running Kali Linux, AFL++ can be installed using the APT package manager.
Once AFL++ is installed, the process of fuzzing a binary becomes unbelievably simple. We only need to complete a few steps to get AFL++ started.
Compile the Program Using ‘afl-clang-fast‘
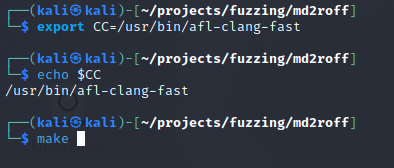
I downloaded the md2roff tool from GitHub onto my local machine and browsed to the folder containing the source code and Makefile. Like any other C/C++ code, we have to compile the program to produce an executable. AFL++ includes a special clang compiler used for instrumentation. Instrumentation is the process of adding code, variables, and symbols to the program to help AFL++ better identify the program flow and produce a crash. Typically the $(CC) variable is used in Makefiles to specify which compiler to use. Let’s point the ‘CC’ environmental variable to the location of our ‘afl-clang-fast’ compiler. Once we have verified this variable is set, we can run the ‘make’ command to compile the source code.
Creating Input and Output Directories
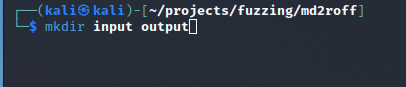
AFL++ requires two folders before it can get started. The first folder will contain our sample input, and the second will be an output directory where AFL++ will write the fuzzing results.
Our input folder needs to contain a test case that will be utilized and modified by AFL++. If we want to fuzz md2roff’s markdown processing functionality, our input directory must have a sample markdown file with primitive contents. This file serves as a ‘base case’ of what program input should resemble.
Once we have verified our sample input we can start AFL++ by using the ‘afl-fuzz’ command:

- afl-fuzz– The AFL++ command used to fuzz a binary
- -i input– The input directory containing our base case
- -o output– The output directory that AFL++ will write our results to
- ./md2roff- The name of the program we want to start with any applicable flags.
- @@– This syntax tells AFL++ that the input is coming from a file instead of stdin
AFL++ Fuzzing
Once AFL++ has initialized, it will continue fuzzing the program with mutated input until you decide to stop it.
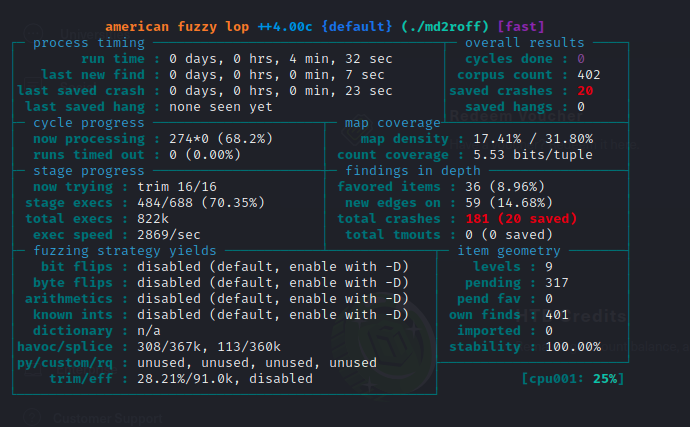
The important sections from the interface are ‘saved crashes’ and ‘exec speed’. ‘Exec Speed’ will show us how fast AFL++ is able to generate new input and fuzz the program. ‘Saved Crashes’ shows us the number of unique crashes the fuzzer was able produce.
It looks like AFL++ discovered a few crashes! Let’s investigate the input that was used to produce the crash. The output/default/crashes directory will contain a file for each unique crash that was generated.
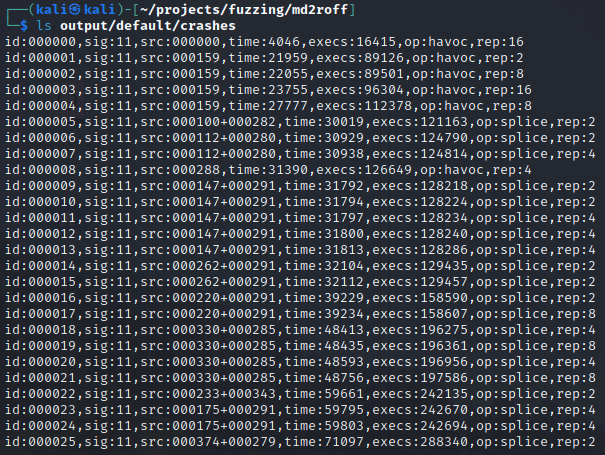
There are plenty of crashes in the output folder to triage. Let’s take a look inside one of them:
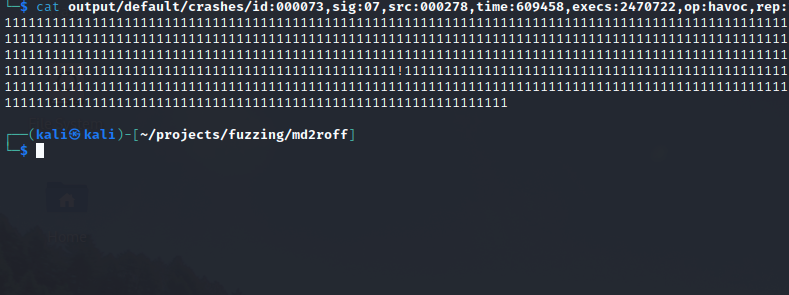
It seems like one of the files that produced a crash was a massive buffer of ‘1’s.
Reproducing the Crash
To recreate the crash I created a markdown document with identical input to the crash file seen in the output/default/crashes directory:

I proceeded to execute the program and use the markdown file as input:

It looks like the program segfaults when trying to process our large buffer of ‘1’s. At a minimum, we have a denial of service condition. If the program is executed as a server or started as a service we could provide malicious input and force the program to crash for every user accessing the service. We can attach GDB to our program and run md2roff a second time to see if we have altered the control flow and overwritten the return address.
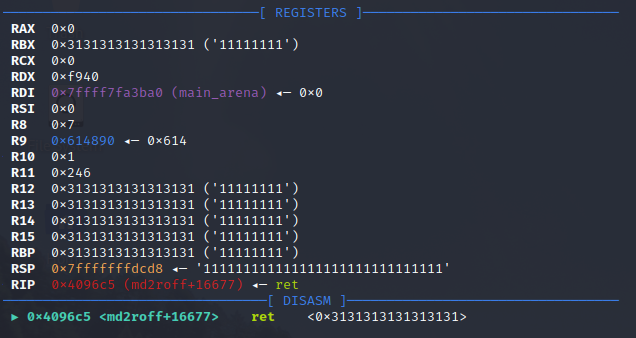
Success! The stack was successfully smashed by our buffer of ‘1’s. From this point forward we could put together an exploit using a binary exploitation technique such as ret2libc or ROP chaining.
Mitigations
Preventing buffer overflows can be achieved by replacing dangerous C functions, such as strcpy() and gets(), with newer implementations like strncpy() and fgets() that specify how many bytes should be read into the buffer.
For example, the following code is vulnerable because the user input could be significantly larger than the available buffer space:
char buf[50];
strcpy(buf, userinput);The following code snippet is an example of how to securely copy data using strncpy(). Instead of reading an undefined amount of bytes into ‘buf’, we can limit the copy operation to the size of our buffer:
char buf[50];
strncpy(buf, userinput, 50);
No responses yet