
Zero-Day Research: 7 CVEs in Libforth
Every month I routinely conduct thorough fuzz testing on various open source libraries to uncover hidden vulnerabilities[…]

Zero-Day Research: CVE-2024-22088 Lotos HTTP Server Use-After-Free
In the realm of cybersecurity, uncovering vulnerabilities is a critical part of securing software applications. Recently, while[…]

Zero-Day Research: CVE-2023-50965 MicroHttpServer Remote Buffer Overflow
MicroHttpServer MicroHttpServer is a simple HTTP web server that implements partial HTTP/1.1. MicroHttpServer can be easily integrated[…]

Zero-Day Research: ehttp Use-after-Free (CVE-2023-52266) and Out-of-Bounds Read (CVE-2023-52267)
The ehttp library advertises itself as a ‘simple HTTP server based on epoll’. The primary goal of[…]

Zero-Day Research: CVE-2022-41220 md2roff Version 1.9 Buffer Overflow
After multiple rounds of fuzz testing, I discovered that md2roff version 1.9 suffered from a stack buffer[…]

Zero-Day Research: PicoC Version 3.2.2 Null Pointer Dereference (CVE-2022-34556) Speedrun
PicoC is a miniature code interpreter developed for C scripting. According to their documentation, PicoC was first[…]

Zero-Day Research: md2roff Version 1.7 Buffer Overflow (CVE-2022-34913)
The best part about security research is the myriad of ways you can find bugs. Sometimes bugs[…]
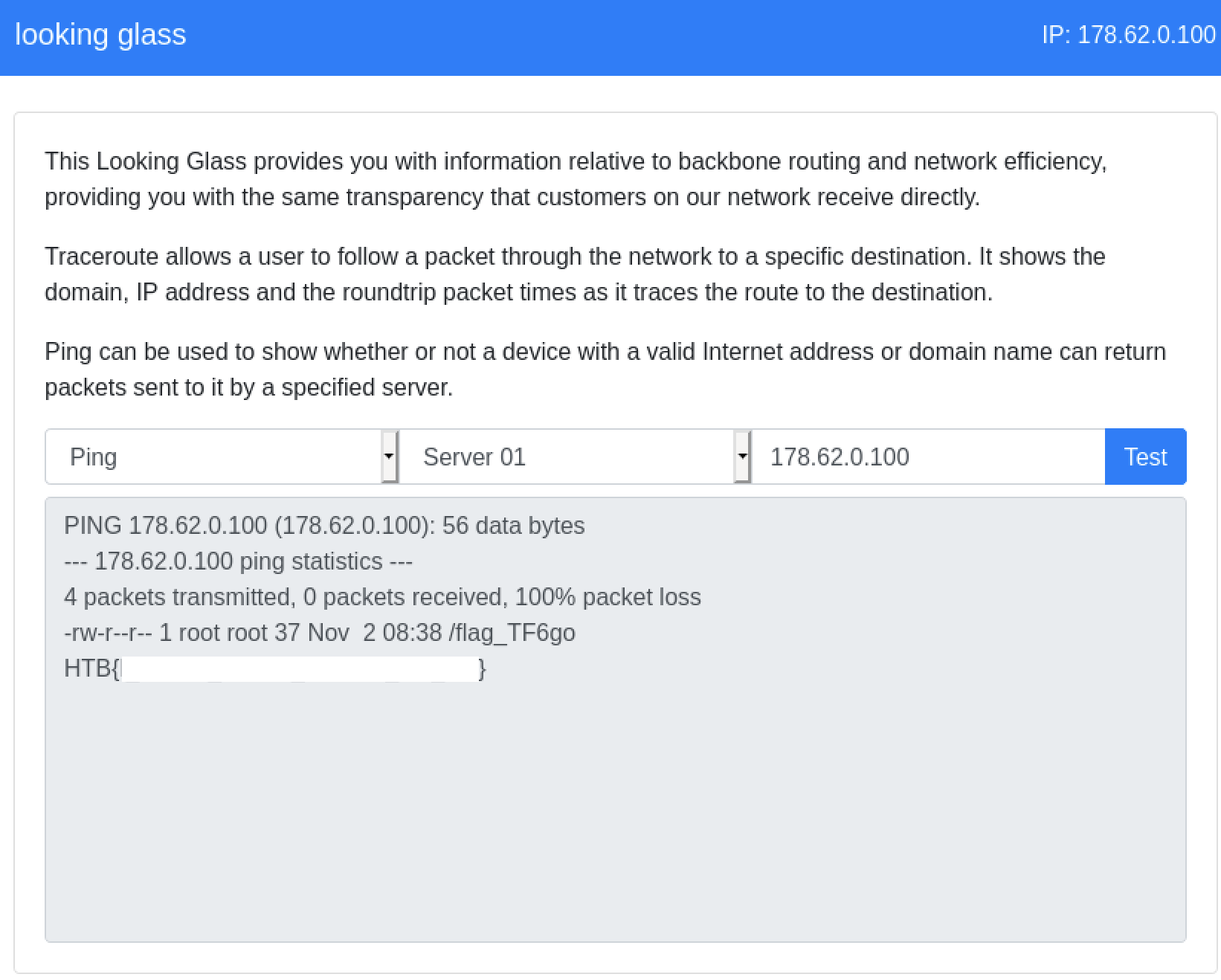
HackTheBox: Looking Glass Web Challenge
Today we will be walking through the ‘Looking Glass’ web challenge from HackTheBox. This specific challenge is[…]