Striking a harmonious balance between high-level abstraction and low-level hardware control, the C programming language proves to be efficient for resource-constrained embedded systems. C programs can be finely tuned to optimize memory usage and execution speed, a critical consideration in embedded applications where resources are at a premium.
Despite the many benefits of the C programming language, C programs are often susceptible to memory corruption vulnerabilities which can be exploited for malicious purposes. Writing secure C code requires careful attention to detail. One method for uncovering memory corruption vulnerabilities is called ‘fuzz testing’.
Fuzz testing, or fuzzing, is a software testing methodology where a program is supplied with invalid, unexpected, or random data, commonly referred to as “fuzz,” with the aim of revealing vulnerabilities and software bugs. The principal objective of fuzz testing is to identify security vulnerabilities, crashes, or unforeseen behaviors in software by exposing it to a diverse array of inputs.
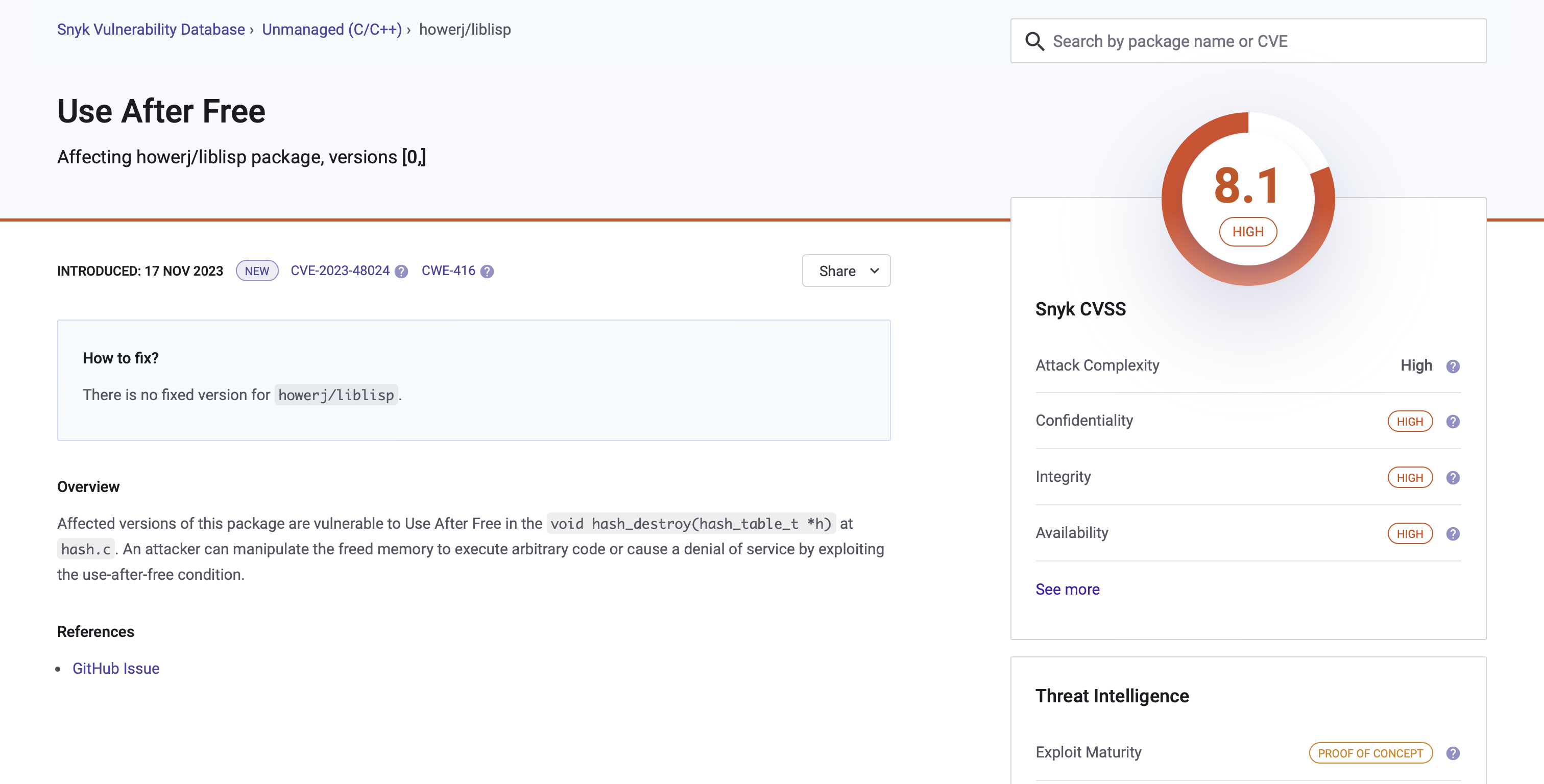
According to their official documentation, Liblisp is a Lisp interpreter that can be used as a library written in c99. When I come across any new software library, I generally perform fuzz testing to search for potential memory corruption vulnerabilities. Throughout the fuzzing process, I discovered a couple of memory corruption bugs in Liblisp through commit 4c65969. I have included all of the files necessary for reproducing each bug on Github.
CVE-2023-48024
The first bug I discovered was a ‘Use-After-Free’ vulnerability in the function void hash_destroy(hash_table_t *h) at hash.c, lines 70-84. The source code can be seen below:
void hash_destroy(hash_table_t * h) {
if (!h)
return;
for (size_t i = 0; i < h->len; i++)
if (h->table[i]) {
hash_entry_t *prev = NULL;
for (hash_entry_t *cur = h->table[i]; cur; prev = cur, cur = cur->next) {
h->free_key(cur->key);
h->free_val(cur->val);
free(prev);
}
free(prev); This type of vulnerability arises when a program continues to use a pointer after the memory it points to has been freed. In this article, we will explore what use-after-free vulnerabilities are, how they occur, and why they are a serious concern for software developers and users.
Understanding Use-After-Free Bugs
Use-after-free vulnerabilities occur when a program accesses memory that has already been deallocated, leading to unpredictable and potentially exploitable behavior. In most programming languages, memory is managed dynamically, with the programmer responsible for allocating and freeing memory as needed. A use-after-free vulnerability occurs when a pointer continues to reference memory that has already been released, creating a situation where an attacker can manipulate the program’s behavior.
How Use-After-Free Vulnerabilities Occur
- Improper Memory Management:
These vulnerabilities often stem from mistakes in memory management. If a developer fails to correctly free memory or attempts to use a pointer after freeing the associated memory, a use-after-free vulnerability can arise. - Dangling Pointers:
Dangling pointers, which point to memory that has already been freed, are a common cause of use-after-free issues. When the program attempts to dereference such pointers, it can lead to unexpected behavior. - Asynchronous Events:
In multithreaded or asynchronous programming, use-after-free vulnerabilities can occur when one part of the program frees memory while another part is still using it.
Implications of Use-After-Free Vulnerabilities:
- Security Exploitation:
Use-after-free vulnerabilities are a popular target for attackers. By exploiting these weaknesses, malicious actors can execute arbitrary code, compromise data integrity, or even gain control over the affected system. - Unpredictable Behavior:
Programs with use-after-free vulnerabilities may exhibit unpredictable behavior, making them challenging to debug. This unpredictability can result in crashes, data corruption, or other serious consequences. - Information Leakage:
In certain scenarios, use-after-free vulnerabilities can lead to the disclosure of sensitive information. Attackers may exploit these vulnerabilities to read data from freed memory, potentially exposing passwords, cryptographic keys, or other confidential information.
Use-After-Free Mitigation Strategies
After freeing pointers, be sure to set each pointer to NULL once they are freed. This effectively prevents the reuse of memory after the memory has been released by a call to ‘free()’. Below are some additional mitigation strategies that can be employed to detect and prevent this vulnerability class.
- Static and Dynamic Analysis Tools:
Utilize static and dynamic analysis tools during the development phase to identify potential use-after-free vulnerabilities before the code is pushed to production. A few examples include Clang Static Analyzer, Semgrep, and Address Sanitizer. - Code Reviews:
Conduct thorough code reviews to catch memory management mistakes and ensure that pointers are handled appropriately. - Use Modern Programming Practices:
Employ modern programming practices that promote safer memory management, such as using RAII (Resource Acquisition Is Initialization) in C++ or employing safer alternatives to manual memory management.
CVE-2023-48025
The second bug I discovered in Liblisp was an out-of-bounds read in the function unsigned get_length(lisp_cell_t * x) at eval.c, line 272. You can view the source code below:
case SYMBOL:
return (uintptr_t)(x->p[1].v); The out-of-bounds read originates from the statement ‘return (uintptr_t)(x->p[1].v);’ when processing a malformed symbol.
Understanding Out-of-Bounds Read Vulnerabilities
Out-of-bounds read vulnerabilities occur when a program accesses data outside the bounds of allocated memory. In simpler terms, it’s like reaching beyond the edges of an array or buffer, attempting to read data that doesn’t belong to the program. This can lead to a cascade of unintended consequences, ranging from unexpected behavior to potential security breaches.
Risks of Out-of-Bounds Read Vulnerabilities
- Information Leakage:
Out-of-bounds reads can result in the exposure of sensitive information stored in adjacent memory locations. Attackers can exploit this vulnerability to obtain data such as passwords, cryptographic keys, or other confidential information. - System Instability:
Reading beyond the allocated memory can cause the program to behave unpredictably, leading to crashes, hangs, or other forms of instability. This not only disrupts the user experience but can also open the door for malicious exploitation. - Security Exploitation:
In the hands of a skilled attacker, out-of-bounds read vulnerabilities can be leveraged as part of more sophisticated attacks. This may include crafting malicious inputs to exploit weaknesses in the software, potentially leading to remote code execution or privilege escalation.
Mitigation Strategies for Out-of-Bounds Reads
- Boundary Checking:
Implement robust boundary checks to ensure that array and buffer accesses stay within the allocated memory. This involves validating indices and lengths before accessing elements. - Use Safe Libraries:
Employ language features and libraries that offer safer alternatives to manual memory manipulation. Languages like Rust and C++ with smart pointers can help mitigate the risks associated with manual memory management. - Code Reviews:
Conduct thorough code reviews to catch boundary-checking mistakes and ensure that array indices are handled accurately. Peer review can be a powerful defense against subtle vulnerabilities. - Testing and Fuzzing:
Implement extensive testing, including boundary and fuzz testing, to discover potential vulnerabilities.
Conclusion
Developing secure programs in low-level languages can be difficult, but offer great performance benefits if done correctly. Developers play a crucial role in mitigating risks by adopting best practices, employing secure coding techniques, and utilizing tools that can detect and prevent such vulnerabilities. As the digital landscape continues to advance, proactive measures are essential to fortify software against these lurking security threats.
If you are interested in learning more about Zero-Day vulnerabilities, check out our Zero-Day Fundamentals course!
References
- https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-48024
- https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-48025
- https://github.com/howerj/liblisp
- https://cwe.mitre.org/data/definitions/416.html
- https://cwe.mitre.org/data/definitions/125.html
No responses yet