
Every month I routinely conduct thorough fuzz testing on various open source libraries to uncover hidden vulnerabilities and report them to the appropriate development team with some suggested patches. Recently, my focus turned to the Libforth library, a widely-used C library for implementing Forth programming language interpreters. Through my rigorous testing, I discovered seven critical CVEs that could have significant implications if left unaddressed.
In this blog post, I will delve into the discovery process of each of these vulnerabilities, providing detailed analyses and mitigation strategies. These vulnerabilities highlight the importance of proactive security measures in software development. For C libraries such as Libforth, I generally use AFL++ to fuzz various portions of the code. Whether you’re a developer, security professional, or enthusiast, this deep dive into Libforth’s CVEs will offer valuable insights into the intricate world of vulnerability research.
AFL++

American Fuzzy Lop (AFL++) is a sophisticated, open-source fuzzing tool widely acclaimed for its effectiveness in identifying software vulnerabilities. Building on the original American Fuzzy Lop (AFL), AFL++ introduces a variety of improvements and new features to enhance the fuzzing process. It automates input generation for software testing by carefully creating inputs that reveal bugs, using genetic algorithms to evolve test cases based on program behavior. This approach allows AFL++ to detect a broad spectrum of errors, from simple crashes to intricate security flaws, making it a vital resource for developers and security researchers dedicated to improving software robustness and security.
Getting started with AFL++ is straightforward, highlighting its user-friendly nature alongside its robust fuzzing capabilities. The first step involves compiling the target software with AFL++’s instrumentation to track execution paths and direct the fuzzing process. This is typically done by setting the CC and CXX environment variables to AFL++’s wrappers (afl-gcc and afl-g++), followed by building the target software as usual. This instrumentation is crucial as it enables AFL++ to determine which parts of the code are exercised by the test cases, thereby optimizing the generation of new inputs to explore previously untested execution paths.
After instrumenting the target software, the next step is to run AFL++ against it. This involves setting up an initial set of inputs (a corpus) and then launching the fuzzer. AFL++ handles the rest by automatically generating new inputs, executing the target program with these inputs, and monitoring for unexpected behaviors such as crashes or hangs. Users can track the fuzzing process in real time through AFL++’s user interface, which offers detailed information about the progress, including the number of test cases executed, coverage achieved, and any discovered bugs. Through its smart input generation and execution monitoring, AFL++ not only uncovers existing vulnerabilities but also provides valuable insights to guide further security assessments and development efforts.
Fuzzing Libforth with AFL++
To incorporate AFL++ instrumentation into our project, we can follow the steps provided below:
Step 1: Download the Project
$ git clone https://github.com/howerj/libforth.git
$ cd libforthStep 2: Modify the Makefile
Modify the makefile and change the CC variable. The CC variable specifies the compiler that will be used to compile the project. We need to change it from GCC to the AFL++ compiler named afl-clang-fast. This will allow AFL++ to add code to the program to collect information during its execution and better fuzz the library:
CC = afl-clang-fastStep 3: Compile Libforth
Compile the project by executing the ‘make’ command from the Linux command line:
$ makeStep 4: Create Input and Output Directories
The next step is to create input and output directories for use with AFL++:
$ mkdir input outputAFL++ and other fuzzing tools work by repeatedly executing the target program with various input data to uncover bugs or vulnerabilities that standard testing might miss. The necessity for input and output directories stems from AFL++’s method of managing and analyzing data throughout its fuzzing process:
Input Directory (input): This directory holds the initial set of test cases, also known as “seed” files, that AFL++ uses to begin fuzzing. The success of the fuzzing process can greatly depend on the quality and relevance of these initial inputs. They should reflect the typical data the program processes but also include edge cases or unusual scenarios. AFL++ uses these seed files to create new, mutated inputs to explore different execution paths within the target program.
Output Directory (output): The output directory is where AFL++ stores the results of its fuzzing campaign, including:
- Crashes: Inputs that cause the program to crash, which may indicate bugs or vulnerabilities.
- Hangs: Inputs that cause the program to hang or run for an unusually long time, suggesting performance issues or deadlocks.
- Unique Paths: AFL++ tracks code coverage and saves inputs that trigger unique code paths, ensuring a comprehensive examination of the program’s behavior.
- Fuzzer Stats: Statistics and progress information, enabling users to monitor the fuzzing process and make informed decisions about continuing or terminating it.
Step 5: Creating Seed Files
Once our directories are created, we need to add a few seed files to the input directory. To create a seed file, we need some example Forth programs that we can provide to AFL++.
For example, you could add all of the Forth files found here and here to the input directory we created. It is always good to have many unique test cases in your input directory to increase overall code coverage, which will increase your likelihood of finding a bug.
Step 6: Starting AFL++
Once you have added your seed files to the input directory, you can start fuzzing Libforth with the following command:
$ afl-fuzz -i input -o output -- ./forth @@The command above is used to start a fuzzing session with AFL++, targeting the forth program. Here’s a breakdown of the command and its components:
afl-fuzz: This is the main executable of AFL++, the fuzzer itself. It’s responsible for generating test cases, running them against the target program, monitoring for crashes or other abnormal behaviors, and then refining its future test cases based on the feedback from these runs.-i input: The-iflag specifies the directory that contains the initial input files or seed files for the fuzzing session. In our case,inputis the directory where we placed ourforthsource code files (test1.fth,test2.fth, etc). AFL++ will use these files as a starting point for generating new test cases.-o output: The-oflag specifies the directory where AFL++ will store its findings, including any inputs that lead to crashes, hangs, or new paths in the code.outputis the directory that will contain these results. AFL++ creates a well-organized structure inside this directory, categorizing the findings for easy analysis.--: This double dash is used in command-line arguments to signify the end of options passed to the command itself (in this case,afl-fuzz). Everything following this is considered an argument to the command or program being fuzzed../forth: This is the target program that AFL++ will fuzz. The./indicates thatforthis located in the current directory. This program will be executed repeatedly with various inputs generated by our fuzzer, based on the initial seed files provided.
Step 7: Monitoring the Output
Once the fuzzer has started, you should see a screen similar to the following, displaying real-time information about the active fuzzing process:
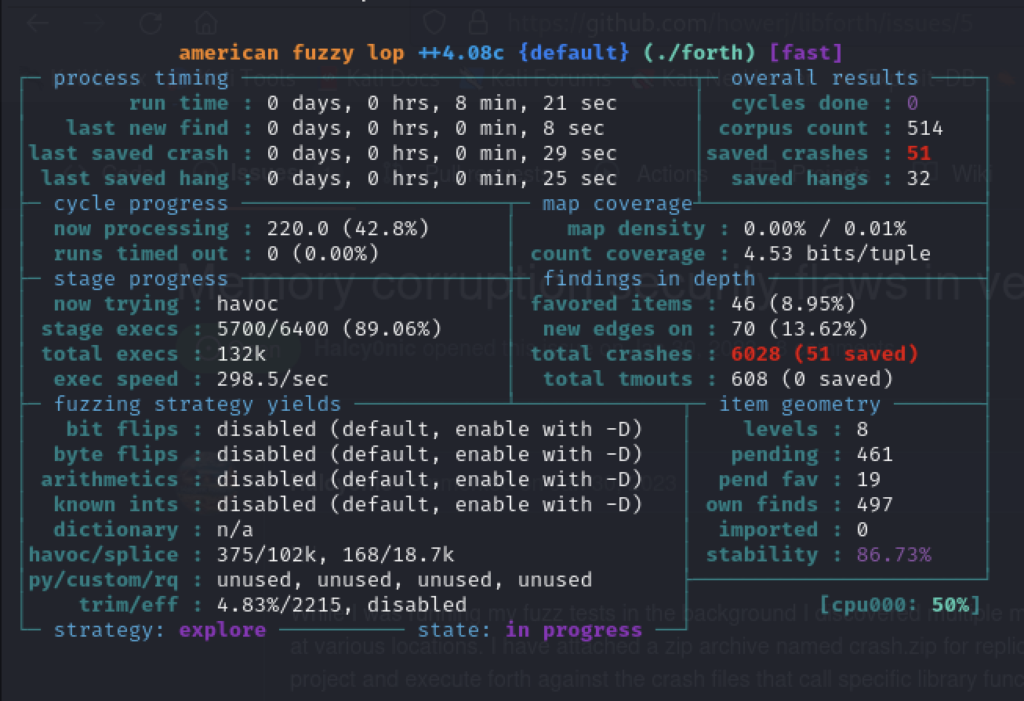
In a short period, AFL++ has already encountered several crashes. The ‘unique crashes’ section provides information about the number of distinct crashes identified by AFL++. A crash typically occurs due to an input that triggers a fatal error in the target program. AFL++ categorizes crashes as unique if they impact different segments of the code. Each input that crashes the program will be saved in the output/default/crashes directory. These files can be used to reproduce the crash and determine whether or not the crash is a result of a memory corruption issue.
Vulnerability Analysis
I generally like to let the fuzzer run for a few days to give it time to discover new code paths and generate a sufficient number of test cases. After letting the fuzzer run for a while, you will notice that AFL++ will produce a very large number of crashes. Many of these crashes are duplicates and some of them are not actual security issues. We have to dig through each of these to figure out which ones are legitimate security concerns that could be exploited in some manner. This process can take quite some time, given the large number of crashes that our fuzzer will discover.
Step 1: Recompile the Project
Recompile the project using address sanitizer (ASan)and debug symbols with GCC or Clang. We don’t need AFL++ here because we simply want to keep track of the execution flow of the program. ASan will assist in detecting any memory corruption issues and pinpoint the exact location where it took place. To add address sanitizer (-fsanitize=address) and debug symbols (-g) to the project we can modify the CFLAGS variable in the makefile:
CFLAGS = -Wall -Wextra -g -pedantic -std=c99 -O2 -fsanitize=address -gTo compile the project, simply type ‘make’ from the libforth folder on the Linux command line:
$ makeStep 2: Execute the Generated Crash Files
Loop through all of the crash files generated by AFL++ and provide them as input to the forth program. ASan will detect each crash, print out the type of memory corruption vulnerability discovered, and provide information about where it took place in the program. For example:
$ for i in `ls output/default/crashes`; do echo $i; ./forth output/default/crashes/$i; doneThis will produce many ASan messages similar to the following:
==1264804==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffd6498d371 at pc 0x55e3edcf16f8 bp 0x7ffd6498d2e0 sp 0x7ffd6498d2d8
WRITE of size 1 at 0x7ffd6498d371 thread T0
#0 0x55e3edcf16f7 in print_cell /dev/shm/libforth/libforth.c:1367
#1 0x55e3edcf1849 in print_stack /dev/shm/libforth/libforth.c:1484
#2 0x55e3edcf1849 in print_stack /dev/shm/libforth/libforth.c:1474
#3 0x55e3edcf5f7a in forth_run /dev/shm/libforth/libforth.c:2554
#4 0x55e3edcee92f in eval_file /dev/shm/libforth/main.c:248
#5 0x55e3edcedf6e in main /dev/shm/libforth/main.c:449
#6 0x7f7afea46189 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#7 0x7f7afea46244 in __libc_start_main_impl ../csu/libc-start.c:381
#8 0x55e3edcee530 in _start (/dev/shm/libforth/forth+0xc530)
Address 0x7ffd6498d371 is located in stack of thread T0 at offset 113 in frame
#0 0x55e3edcf146f in print_cell /dev/shm/libforth/libforth.c:1357
This frame has 1 object(s):
[48, 113) 's' (line 1359) <== Memory access at offset 113 overflows this variable
HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork
(longjmp and C++ exceptions *are* supported)
SUMMARY: AddressSanitizer: stack-buffer-overflow /dev/shm/libforth/libforth.c:1367 in print_cell
Shadow bytes around the buggy address:
0x10002c929a10: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a20: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a30: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x10002c929a60: f1 f1 f1 f1 f1 f1 00 00 00 00 00 00 00 00[01]f3
0x10002c929a70: f3 f3 f3 f3 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929a90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929aa0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x10002c929ab0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==1264804==ABORTING
Explanation of the ASAN Output
Here’s a breakdown of the key information provided by ASan and what it means:
Error Type:
==1264804==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffd6498d371This error means that the program wrote to a memory location that is outside the bounds of a stack-allocated buffer.
Location of the Error:
at pc 0x55e3edcf16f8 bp 0x7ffd6498d2e0 sp 0x7ffd6498d2d8
WRITE of size 1 at 0x7ffd6498d371 thread T0
#0 0x55e3edcf16f7 in print_cell /dev/shm/libforth/libforth.c:1367The error occurred in the print_cell function, specifically at line 1367 in the libforth.c file. The problematic write operation was to address 0x7ffd6498d371.
Call Stack:
#0 0x55e3edcf16f7 in print_cell /dev/shm/libforth/libforth.c:1367
#1 0x55e3edcf1849 in print_stack /dev/shm/libforth/libforth.c:1484
#2 0x55e3edcf1849 in print_stack /dev/shm/libforth/libforth.c:1474
#3 0x55e3edcf5f7a in forth_run /dev/shm/libforth/libforth.c:2554
#4 0x55e3edcee92f in eval_file /dev/shm/libforth/main.c:248
#5 0x55e3edcedf6e in main /dev/shm/libforth/main.c:449
#6 0x7f7afea46189 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#7 0x7f7afea46244 in __libc_start_main_impl ../csu/libc-start.c:381
#8 0x55e3edcee530 in _start (/dev/shm/libforth/forth+0xc530)This shows the sequence of function calls leading up to the error, starting from the print_cell function and going up to the main function.
Specific Buffer Information:
Address 0x7ffd6498d371 is located in stack of thread T0 at offset 113 in frame
#0 0x55e3edcf146f in print_cell /dev/shm/libforth/libforth.c:1357The problematic address is within the stack frame of the print_cell function, specifically at offset 113 in the buffer ‘s’ defined at line 1359.
This frame has 1 object(s):
[48, 113) 's' (line 1359) <== Memory access at offset 113 overflows this variableThe buffer ‘s’ starts at offset 48 and ends at 113, meaning the write at 113 overflows this buffer.
Shadow Bytes:
Shadow bytes around the buggy address:
0x10002c929a10: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
...
=>0x10002c929a60: f1 f1 f1 f1 f1 f1 00 00 00 00 00 00 00 00[01]f3The shadow memory provides a detailed view of the memory around the problematic address. The f1 indicates the left redzone of the stack, and f3 indicates the right redzone. The 01 suggests a single byte overflow.
Overview of Discovered Vulnerabilities
After triaging all of the vulnerabilities, they were responsibly disclosed to the appropriate development team. Below is a summary of each vulnerability and the corresponding CVE ID:
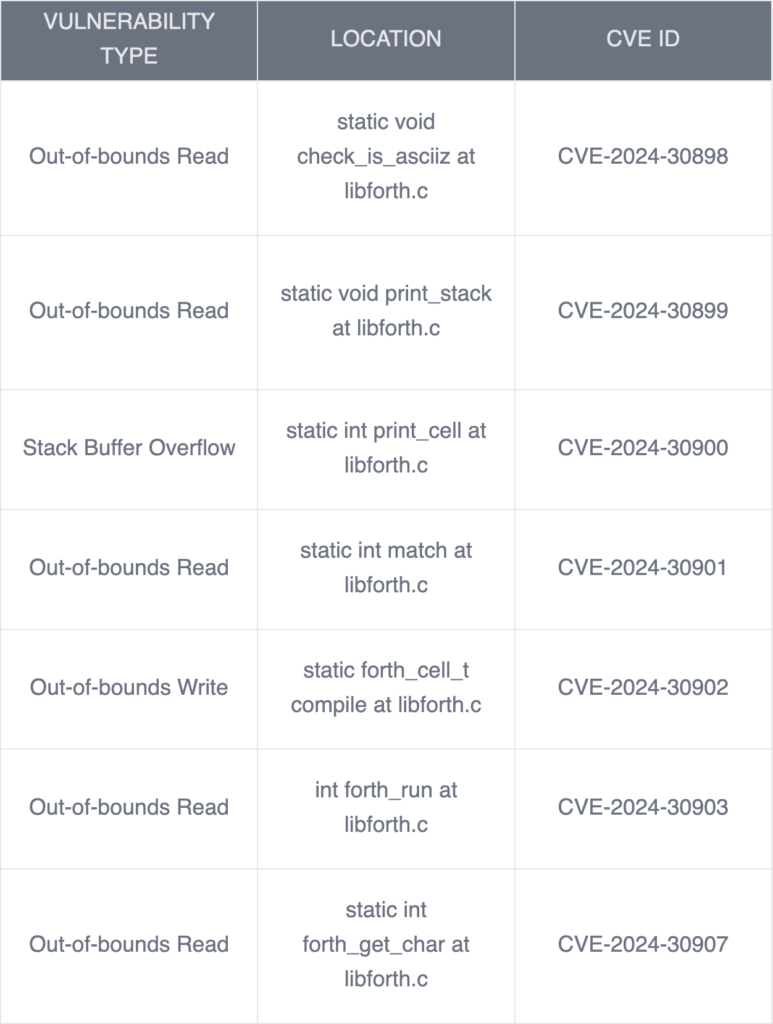
CVE-2024-30898: Out of Bounds Read in check_is_asciiz
- Function:
check_is_asciiz(jmp_buf *on_error, char *s, forth_cell_t end) - Location:
libforth.c, line 1436 - Issue: The function attempts to read beyond the allocated memory by accessing
*(s + end), which could result in a segmentation fault or other undefined behavior. - Replication File:
check_is_asciiz_line_1436.fth
CVE-2024-30899: Out of Bounds Read in print_stack
- Function:
print_stack(forth_t *o, FILE *out, forth_cell_t *S, forth_cell_t f) - Location:
libforth.c, line 1481 - Issue: The function attempts to read beyond the bounds of the stack by accessing
*(o->S + i + 1). - Replication File:
print_stack_line_1481.fth
CVE-2024-30900: Stack-Based Buffer Overflow in print_cell
- Function:
print_cell(forth_t *o, FILE *out, forth_cell_t u) - Location:
libforth.c, line 1367 - Issue: A stack-based buffer overflow occurs when the function writes more data than the allocated stack buffer can hold, specifically in the statement
s[i++] = conv[u % base]. - Replication File:
print_cell_line_1367.fth
CVE-2024-30901: Out of Bounds Read in match
- Function:
match(forth_cell_t *m, forth_cell_t pwd, const char *s) - Location:
libforth.c, line 1306 - Issue: The function attempts to read beyond the bounds of the array
mby accessingm[pwd + 1]. - Replication File:
match_line_1306.fth
CVE-2024-30902: Out of Bounds Write in compile
- Function:
compile(forth_t *o, forth_cell_t code, const char *str, forth_cell_t compiling, forth_cell_t hide) - Location:
libforth.c, line 1241 - Issue: The function writes data beyond the bounds of the allocated memory by copying a string into an insufficiently sized buffer using
strcpy((char *)(o->m + head), str). - Replication File:
compile_line_1241.fth
CVE-2024-30903: Out of Bounds Read in forth_run
- Function:
forth_run(forth_t *o) - Location:
libforth.c, various lines - Issue: Multiple instances of out-of-bounds read occur within the
forth_runfunction, such as when executingmemcmp,memchr,memset,fflush,fwrite, andferroroperations. - Replication Files: Multiple, including
forth_run_line_2730.fth,forth_run_line_2721.fth,forth_run_line_2716.fth,forth_run_line_2665.fth,forth_run_line_2666.fth,forth_run_line_2623.fth
CVE-2024-30907: Out of Bounds Read in forth_get_char
- Function:
forth_get_char(forth_t *o) - Location:
libforth.c, line 1091 - Issue: The function attempts to read beyond the bounds of the array by accessing
r = fgetc((FILE*)(o->m[FIN])). - Replication File:
forth_get_char_line_1091.fth
Recommendations for Mitigation
The identified vulnerabilities in Libforth highlight common issues in C programming related to memory management. Addressing these vulnerabilities requires a combination of input validation, bounds checking, safe coding practices, and continuous testing. Implementing these mitigations can significantly enhance the security of the library.
- Input Validation: Implement comprehensive input validation to ensure that data processed by these functions are within the expected bounds.
- Bounds Checking: Introduce bounds checking in all functions that read from or write to memory to prevent out-of-bounds access.
- Use Safe Functions: Replace unsafe functions like
strcpywith safer alternatives likestrncpyor implement custom bounds-checked versions. - Fuzz Testing: Continue to use fuzz testing to identify potential vulnerabilities early in the development cycle.
- Code Review: Conduct regular code reviews focusing on security, especially for areas involving memory management.
For a comprehensive list of patches and mitigations, see the official Github Issue.
No responses yet