
Introduction
In the realm of computer science, abstract concepts often find practical applications. The Lambda Calculus Interpreter (LCI) is a quintessential tool that marries theoretical foundations with real-world utility. At its core, lambda calculus serves as the bedrock of functional programming, offering a minimalist framework to explore computation through the lens of function abstraction and application. Imagine, for a moment, a universe where all operations are distilled into the simple act of applying functions to arguments. This is the universe of lambda calculus, where even the most complex computations are reduced to their bare essentials.
Enter LCI, a robust interpreter and programming language that not only demystifies lambda calculus but also brings its elegant simplicity into the hands of developers and researchers. Equipped with features that extend beyond mere theoretical exploration—such as recursion, user-defined operators, and multiple evaluation strategies—LCI bridges the gap between the abstract beauty of lambda calculus and its practical applications. Through LCI, users can delve into the fascinating world of Church Numerals, representing integers in a purely functional manner, and unleash the full potential of function-based computation.
Furthermore, LCI’s prowess is tested and secured using cutting-edge tools like AFL++ (American Fuzzy Lop Plus Plus), an advanced fuzzing tool that helps uncover vulnerabilities by automatically generating test cases that push the software to its limits. Fuzzing, in this context, is the process of intelligently bombarding LCI with a wide range of inputs to ensure it can handle unexpected or maliciously crafted data without compromising security. Over the course of my detailed security analysis on LCI, I identified several vulnerabilities, each of which has been officially recognized with a CVE designation by MITRE.
Despite its brilliance, LCI is not immune to the vulnerabilities that plague software systems. A meticulous investigation reveals multiple memory corruption vulnerabilities, ranging from stack buffer overflows to invalid pointer dereferences. Depending on the environment and implementation details, these vulnerabilities could lead to denial of service, information disclosure, or even remote code execution. Such findings underscore the importance of security in the design and deployment of interpreters like LCI.
AFL++

American Fuzzy Lop (AFL++) is an advanced, open-source fuzzing tool that has gained widespread recognition for its efficiency in finding vulnerabilities within software. Building on the legacy of the original American Fuzzy Lop (AFL), AFL++ introduces numerous enhancements and new features aimed at improving the fuzzing process. It automates the task of input generation for testing programs, meticulously crafting inputs that expose bugs by monitoring the program’s behavior and leveraging genetic algorithms to evolve test cases. This methodology enables AFL++ to uncover a wide range of errors, from simple crashes to complex security vulnerabilities, making it an invaluable tool for developers and security researchers focused on enhancing software reliability and security.
Getting started with AFL++ is straightforward, emphasizing its ease of use alongside its powerful fuzzing capabilities. The initial step involves compiling the target software with AFL++’s instrumentation to monitor the execution path and guide the fuzzing process. This is typically achieved by setting the CC and CXX environment variables to AFL++’s wrappers (afl-gcc and afl-g++) and then building the target software as usual. This instrumentation is critical as it allows AFL++ to identify which parts of the code are being exercised by the test cases, thus optimizing the generation of new inputs to explore uncharted paths within the program’s execution space.
Once the target software is instrumented, the next step is to run AFL++ against it, which involves setting up an initial set of inputs (a corpus) and then starting the fuzzer. AFL++ takes care of the rest, automatically generating new inputs, executing the target program with those inputs, and monitoring for unexpected behaviors such as crashes or hangs. Users can observe the fuzzing process in real-time through AFL++’s user interface, which provides detailed information about the progress, including the number of test cases executed, the coverage achieved, and any bugs discovered. Through its intelligent input generation and execution monitoring, AFL++ not only identifies existing vulnerabilities but also provides insights that can guide further security assessments and development efforts.
Fuzzing LCI With AFL++
Like most C and C++ projects, AFL++ is a great fuzzing tool for finding memory corruption vulnerabilities and various software bugs. To build the project with AFL++ instrumentation, we can follow the steps outlined below:
$ git clone https://github.com/chatziko/lci.git
$ cd lci
$ git submodule init
$ git submodule update
$ export CC=afl-gcc
$ export CXX=afl-g++
$ cmake -B build
$ cd build
$ makeThese commands are part of a process to download, prepare, and build a software project from its source code, with a specific focus on using AFL++ for fuzz testing. Here’s what each command does:
git clone https://github.com/chatziko/lci.git:- This command uses Git, a version control system, to clone or copy the entire repository from the provided URL to your local machine. The repository in question is
lci, a Lambda Calculus Interpreter. Cloning is the first step in working with a copy of the source code on your computer.
- This command uses Git, a version control system, to clone or copy the entire repository from the provided URL to your local machine. The repository in question is
cd lci:- After cloning, this command changes the directory to the
lcifolder that was just created by thegit clonecommand.cdstands for “change directory,” and it’s used to navigate into directories in your terminal or command prompt.
- After cloning, this command changes the directory to the
git submodule init:- This initializes your local configuration file for submodules. A submodule is a repository embedded inside another repository. The
lciproject uses submodules to include and manage dependencies or external libraries. This command sets up the necessary information to later fetch the submodules’ data.
- This initializes your local configuration file for submodules. A submodule is a repository embedded inside another repository. The
git submodule update:- After initialization, this command fetches all the data from the submodules and checks out the specified commit so that the submodule is at the state the main repository expects it to be. This ensures that you have the exact version of the dependencies that the project requires.
export CC=afl-gccandexport CXX=afl-g++:- These commands set environment variables
CCandCXXtoafl-gccandafl-g++respectively.CCandCXXare standard environment variables that specify the C and C++ compilers to be used for building the software. By setting these to AFL++’s compilers (afl-gcc and afl-g++), you instruct the build system to use AFL++ for compiling the project. This is necessary for instrumenting the code, which is required for fuzz testing.
- These commands set environment variables
cmake -B build:- This command invokes CMake, a cross-platform build system generator, to configure the project and generate build files in the
builddirectory. The-Boption specifies the directory for the build files, creating it if it doesn’t exist. CMake reads the configuration (CMakeLists.txt) and sets up everything needed to build the project according to the environment (which now includes AFL++ compilers).
- This command invokes CMake, a cross-platform build system generator, to configure the project and generate build files in the
cd build:- Changes the directory to the
buildfolder where the build configuration and files are located. This is done to execute the make command in the correct directory, where the Makefile generated by CMake is located.
- Changes the directory to the
make:- Finally, this command compiles the project using the Makefile generated by CMake.
makefollows the instructions in the Makefile to compile the project’s source code into an executable binary. Since the project was configured with AFL++ compilers, the resulting binary is instrumented for fuzz testing with AFL++.
- Finally, this command compiles the project using the Makefile generated by CMake.
Following these commands step-by-step, you set up a development environment tailored for fuzz testing with AFL++, from cloning the project’s source code to compiling an instrumented version of the software. Once the project is compiled, we can start fuzzing LCI.
Creating Input and Output Directories
The next step is to create input and output directories for use with AFL++:
$ mkdir input outputAFL++ (and fuzzing tools in general) operates by continuously running the target program with a variety of input data to discover bugs or vulnerabilities that might not be apparent through standard testing methods. The need for input and output directories arises from how AFL++ manages and analyzes the data during its fuzzing process:
- Input Directory (
input): This directory is used to store the initial set of test cases that AFL++ will use as a starting point for fuzzing. These test cases are often known as “seed” files. The effectiveness of the fuzzing process can depend significantly on the quality and relevance of these initial inputs. They should be representative of the typical data the program expects to process but can also include edge cases or unusual scenarios. AFL++ uses these seeds to generate new, mutated inputs that explore different execution paths within the target program. - Output Directory (
output): AFL++ uses the output directory to store the results of its fuzzing campaign, including:- Crashes: Inputs that caused the program to crash, potentially indicating bugs or vulnerabilities.
- Hangs: Inputs that cause the program to hang or execute for an unusually long time, suggesting performance issues or deadlocks.
- Unique Paths: AFL++ monitors code coverage and stores inputs that trigger unique code paths, helping to ensure a thorough exploration of the program’s behavior.
- Fuzzer Stats: Statistics and progress information, allowing users to monitor the fuzzing process and make informed decisions about its continuation or termination.
The separation into input and output directories helps in organizing the fuzzing workflow and enables AFL++ to efficiently manage its data. Users can easily supply initial test cases and review the findings by looking into the respective directories. This setup is part of AFL++’s design to automate the fuzzing process as much as possible, requiring minimal intervention from the user while providing detailed feedback about the software’s behavior under test.
Creating Seed Files
Once our directories are created, lets add a few seed files to the input directory. From the build directory, execute the following commands:
$ echo "1+1" | tee -a ./input/test1.lci
$ echo "1*1" | tee -a ./input/test2.lci
$ echo "1/1" | tee -a ./input/test3.lci
$ echo "1-1" | tee -a ./input/test4.lciEach of the commands listed performs a series of operations involving echo, tee, and redirection to create seed files with basic arithmetic expressions. Here’s a detailed look at one of the commands as an example:
echo "1+1": This part of the command uses theechocommand to produce the string “1+1”.echosimply outputs whatever text is provided to it as an argument.|: This is the pipe operator. It takes the output of the command on its left (in this case, the output fromecho "1+1") and uses it as the input for the command on its right.tee -a ./input/test1.lci: Theteecommand reads from standard input and writes to both standard output (so you can see the result on your terminal) and to the file you specify. The-aoption means “append mode”, so instead of overwriting the contents of./input/test1.lci,teewill add to it. Iftest1.lcidoesn’t exist,teecreates it. The path./input/test1.lcispecifies the filetest1.lciinside theinputdirectory relative to your current location.
The same explanation applies to the other commands listed, with the only differences being the arithmetic operation within the echo command and the filename to which tee writes. The use of basic arithmetic operations for the seed files is particularly strategic, considering that LCI operates as a lambda calculus interpreter. Lambda calculus fundamentally deals with functions, abstraction, and application, often applied within mathematical contexts. For example, if you try the LCI demo application you can see that it expects an arithmetic expression:
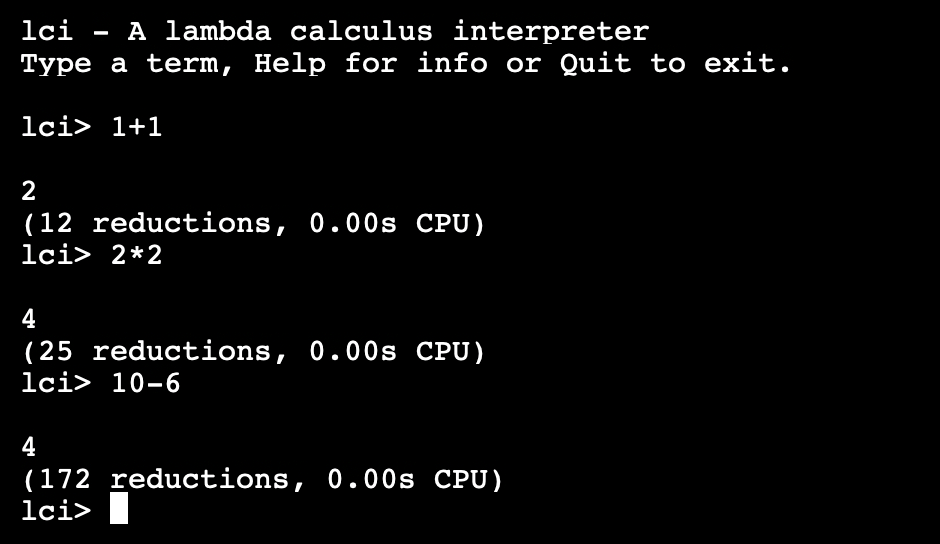
By introducing arithmetic expressions as input, we align closely with the nature of lambda calculus, allowing LCI to process inputs that are not only relevant but also reflective of the complex mathematical computations it’s designed to interpret. This approach ensures that our seed files are not just random data but meaningful expressions that engage the core functionalities of LCI, facilitating a more effective exploration of its capabilities and potential vulnerabilities through the fuzzing process.
Importance of Creating Seed Files
Seed files are crucial for the fuzzing process for several reasons:
- Starting Point: They provide AFL++ with a starting point for its fuzzing operations. By analyzing and mutating these initial inputs, AFL++ generates new test cases designed to explore different execution paths within the target application.
- Efficiency: Well-chosen seed files can significantly increase the efficiency of the fuzzing process. If the seeds are representative of typical or edge-case scenarios that the application might handle, AFL++ can more quickly uncover bugs or vulnerabilities related to these scenarios.
- Coverage: The quality and diversity of the seed files can influence the code coverage achieved during fuzzing. Higher coverage means that more parts of the application’s code are being executed and tested, increasing the likelihood of discovering issues.
- Reducing Time: Good seed files can reduce the time it takes for AFL++ to find bugs by guiding the fuzzer toward more interesting and relevant parts of the application’s input space.
By manually creating seed files with basic arithmetic operations for LCI, you are seeding the fuzzing process with simple yet varied examples of what LCI might be expected to handle. This variety can help ensure that AFL++ explores different code paths related to arithmetic operations, potentially uncovering bugs or vulnerabilities associated with them.
Starting AFL++
Now that everything is properly setup, we can start our fuzzer:
afl-fuzz -i input -o output -- ./lciThe command above is used to start a fuzzing session with AFL++, targeting the lambda calculus interpreter. Here’s a breakdown of the command and its components:
afl-fuzz: This is the main executable of AFL++, the fuzzer itself. It’s responsible for generating test cases, running them against the target program, monitoring for crashes or other abnormal behaviors, and then refining its future test cases based on the feedback from these runs.-i input: The-iflag specifies the directory that contains the initial input files or seed files for the fuzzing session. In our case,inputis the directory where we placed our seed files (test1.lci,test2.lci,test3.lci, andtest4.lci). AFL++ will use these files as a starting point for generating new test cases.-o output: The-oflag specifies the directory where AFL++ will store its findings, including any inputs that lead to crashes, hangs, or new paths in the code.outputis the directory that will contain these results. AFL++ creates a well-organized structure inside this directory, categorizing the findings for easy analysis.--: This double dash is used in command-line arguments to signify the end of options passed to the command itself (in this case,afl-fuzz). Everything following this is considered an argument to the command or program being fuzzed../lci: This is the target program that AFL++ will fuzz. The./indicates thatlciis located in the current directory. This program will be executed repeatedly with various inputs generated by our fuzzer, based on the initial seed files provided.
Once the fuzzer has started, you should see a screen similar to the following, displaying real-time information about the active fuzzing process:
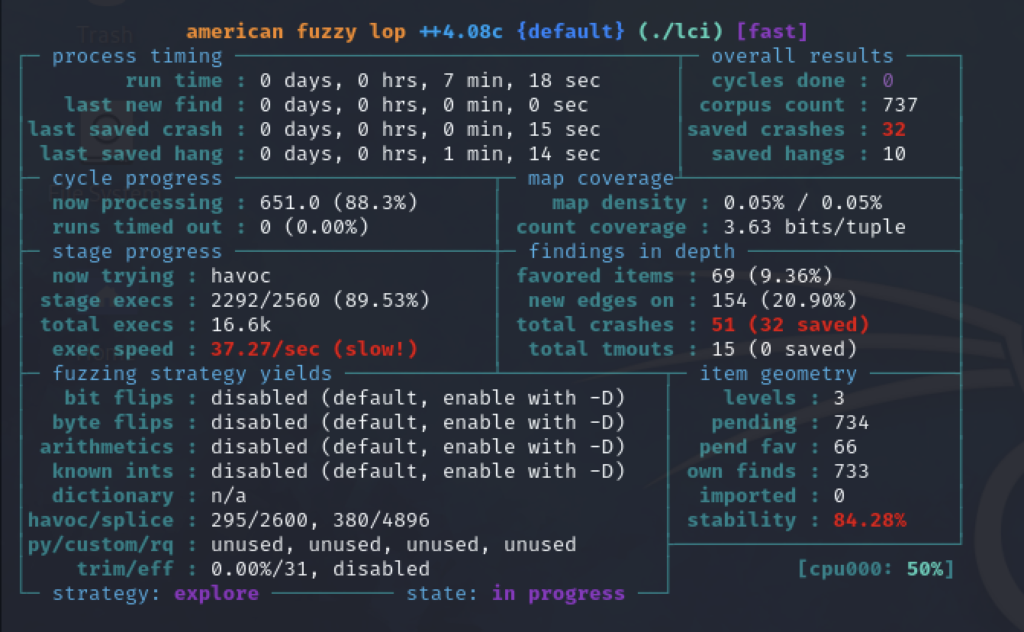
What happens during fuzzing?
- Initialization: AFL++ begins by analyzing the target program (
lci) using the seed inputs provided in theinputdirectory. It determines code coverage and identifies which parts of the code are exercised by the seed inputs. - Input Generation and Mutation: Based on the initial seeds, AFL++ generates new test cases by mutating these seeds in various ways, such as flipping bits, adding or removing bytes, or inserting known interesting values.
- Execution Monitoring: Each generated input is fed to the
lciprogram, and AFL++ monitors the execution for crashes, hangs, or any new code paths triggered. This monitoring is made possible by the instrumentation that was added to the program during compilation withafl-gccorafl-g++. - Feedback Loop: Information gathered during execution (e.g., new code paths, crashes) is used to refine the input generation process. This feedback loop allows AFL++ to “learn” which mutations are more likely to yield interesting results, optimizing the fuzzing process over time.
- Reporting: Findings, including any inputs that cause crashes or hangs, are saved in the
outputdirectory for later analysis.
Verifying Crashes
After just a few minutes, we can verify that AFL++ has already come across a few crashes. The ‘unique crashes‘ section displays the number of unique crashes that AFL++ has found. A crash is typically caused by an input that triggers a fatal error in the target program. AFL++ considers crashes unique if they affect different parts of the code.
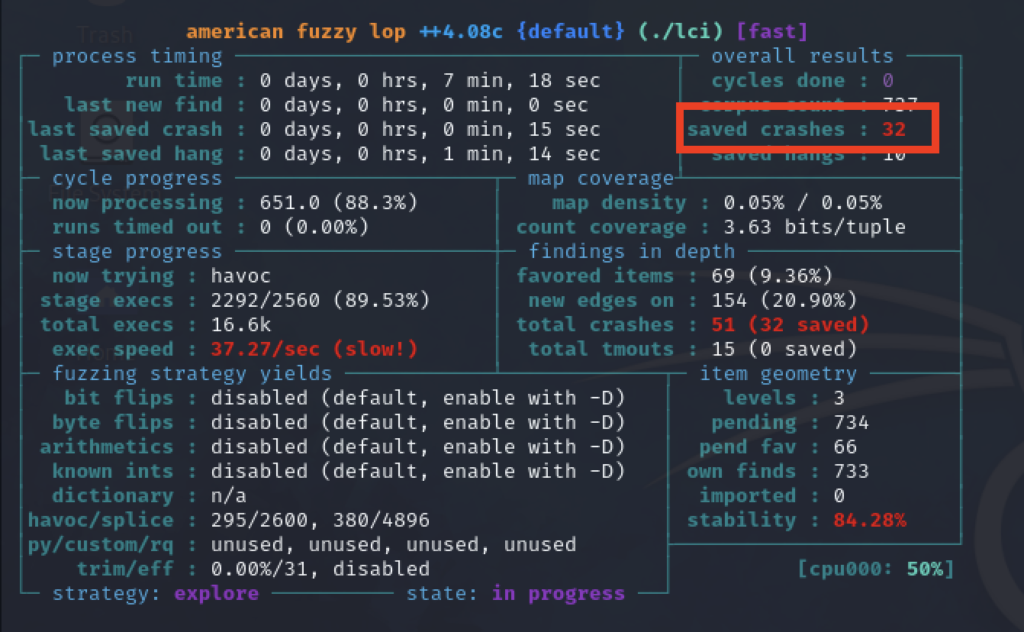
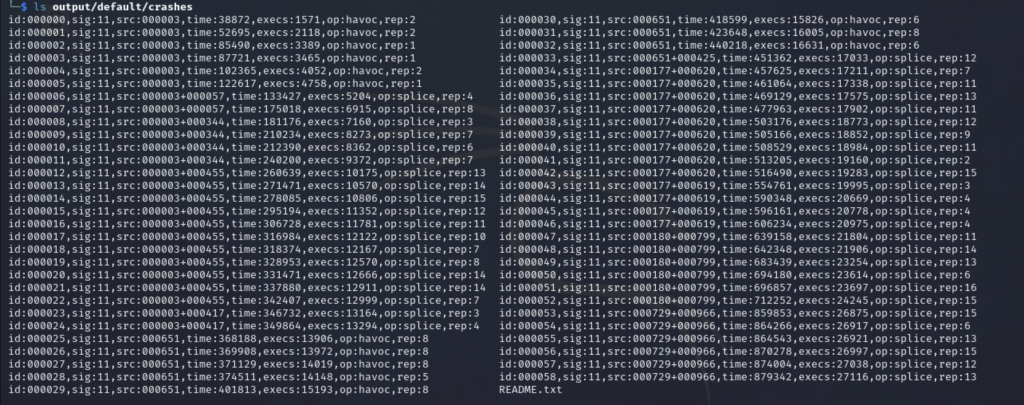
In AFL++, crashes discovered during the fuzzing process are saved in the output directory that you specify when starting AFL++ with the -o option. Within this output directory, AFL++ organizes its findings into several subdirectories for easy analysis. Crashes, in particular, are saved in a subdirectory named crashes. Here’s how it typically looks:
- Output Directory (
-o output): The main directory specified for storing the results of the fuzzing session.- output/default/
crashesSubdirectory: Contains inputs that led to crashes of the target program. Each file in this directory represents a unique input that caused a crash during the fuzzing process.
- output/default/
Within the crashes subdirectory, you’ll find files prefixed with identifiers like id:, followed by a sequence number, and possibly a description of the signal that caused the crash (e.g., SIGSEGV, SIGILL, etc.). These files are the actual inputs that you can feed back into the target program to reproduce the crashes. Reproducing the crashes with these inputs is a critical step in diagnosing and fixing the underlying issues in the program.
AFL++ also creates a README.txt file in the crashes directory, providing information about the crash files, including how to reproduce the crashes using the stored inputs. This aids in systematic debugging and vulnerability assessment.
Further Crash Investigation
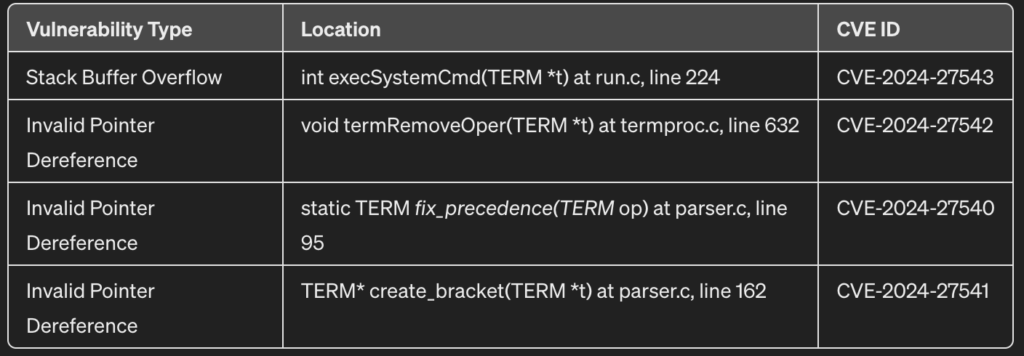
After triaging each of the crashes, I confirmed a total of 4 unique memory corruption vulnerabilities through commit 2deb0d4 (Version 1.0) at the following locations:
Depending on the environment and implementation details, these vulnerabilities could lead to denial of service, information disclosure, or even remote code execution. I’ve included a zip file on Github that contains all of the proof of concept files needed for reproducing each issue.
Building LCI With Address Sanitizer and Debug Symbols
I saved each of the crash files and recompiled the project with address sanitizer (ASan) and debug symbols (on Linux) to help track down the location of each vulnerability. This can be done with the following commands:
$ git clone https://github.com/chatziko/lci.git
$ cd lci
$ git submodule init
$ git submodule update
$ export ASAN_OPTIONS=detect_leaks=0 #This is to ignore memory leaks found when building the project
$ cmake -DCMAKE_C_FLAGS="-fsanitize=address -g" -DCMAKE_CXX_FLAGS="-fsanitize=address -g" -B build
$ cd build
$ makeAfter running these commands, the LCI binary should be built with ASan and debug symbols. The compilation steps for Windows might differ slightly. In the above commands, I ignored memory leaks that ASan detected while building the project. If you are interested in viewing those, don’t execute the fifth command and you’ll see the leaks detected once you run ‘make‘.
CVE-2024-27543
A stack buffer overflow vulnerability has been discovered in int execSystemCmd(TERM *t) at run.c, line 224. This vulnerability is triggered when processing certain input that leads to an unexpected code path, attempting to overwrite data on the stack.
while(t->type == TM_APPL) {
*sp++ = t->rterm;
parno++;
t = t->lterm;
}Triggering the Vulnerability
To trigger the vulnerability, I’ve provided a proof of concept input that you can feed into LCI named bufferoverflow_execSystemCmd. We can send the contents of this text file into lci to view the crash:
$ cat bufferoverflow_execSystemCmd | lciAddress Sanitizer Output
ASan catches the crash and provides some helpful information about where in the code this takes place:
=================================================================
==520025==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fc0ab437780 at pc 0x55ff0ba73afb bp 0x7ffd39d78f60 sp 0x7ffd39d78f58
WRITE of size 8 at 0x7fc0ab437780 thread T0
#0 0x55ff0ba73afa in execSystemCmd /dev/shm/lci/src/run.c:224
#1 0x55ff0ba73cab in execTerm /dev/shm/lci/src/run.c:105
#2 0x55ff0ba7890b in d_final_reduction_code_5_8_gram /dev/shm/lci/src/grammar.g:34
#3 0x55ff0ba90eb9 in commit_tree /dev/shm/lci/dparser/parse.c:1617
#4 0x55ff0ba9081a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#5 0x55ff0ba9770d in dparse /dev/shm/lci/dparser/parse.c:2121
#6 0x55ff0ba7164b in parse_string /dev/shm/lci/src/parser.c:35
#7 0x55ff0ba6ac9a in main /dev/shm/lci/src/main.c:105
#8 0x7fc0ad2456c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#9 0x7fc0ad245784 in __libc_start_main_impl ../csu/libc-start.c:360
#10 0x55ff0ba6b260 in _start (/dev/shm/lci/build/lci+0x3b260) (BuildId: ff37cd476b852db6d5e5bad433ac32fa2ca6f5de)
Address 0x7fc0ab437780 is located in stack of thread T0 at offset 128 in frame
#0 0x55ff0ba7333f in execSystemCmd /dev/shm/lci/src/run.c:212
This frame has 1 object(s):
[48, 128) 'stack' (line 219) <== Memory access at offset 128 overflows this variable
HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork
(longjmp and C++ exceptions *are* supported)
SUMMARY: AddressSanitizer: stack-buffer-overflow /dev/shm/lci/src/run.c:224 in execSystemCmd
Shadow bytes around the buggy address:
0x7fc0ab437500: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7fc0ab437580: f5 f5 f5 f5 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437600: f1 f1 f1 f1 00 00 02 f2 f2 f2 f2 f2 00 00 02 f3
0x7fc0ab437680: f3 f3 f3 f3 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437700: f1 f1 f1 f1 f1 f1 00 00 00 00 00 00 00 00 00 00
=>0x7fc0ab437780:[f3]f3 f3 f3 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437800: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437880: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437900: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437980: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7fc0ab437a00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==520025==ABORTING The AddressSanitizer output indicates a stack-buffer-overflow error. This type of error occurs when a program writes to a memory location on the stack outside of the allocated bounds for a stack variable. In this case, the overflow is happening with the stack array in the execSystemCmd function, which is defined with a fixed size of 10 elements.
The overflow occurs because the code does not check if the number of parameters (parno) exceeds the size of the stack array before incrementing the sp pointer and writing to the next element. This can lead to writing beyond the end of the stack array if more than 10 parameters are processed, causing memory corruption and potentially leading to a crash or other undefined behavior.
Mitigation
I’ve provided an immediate workaround example to mitigate the vulnerability until a more comprehensive patch is released. This will apply input validation and sanitization measures to reject potentially malicious or malformed inputs before processing them with LCI.
To fix this vulnerability, we can add a check to ensure that the sp pointer does not exceed the bounds of the stack array. Here’s an updated version of the execSystemCmd function with a bounds check:
int execSystemCmd(TERM *t) {
// interned constants, initialize on first execution
static char* icon[sizeof(str_constants)/sizeof(char*)];
if(icon[0] == NULL)
for(int i = 0; i < sizeof(str_constants)/sizeof(char*); i++)
icon[i] = str_intern(str_constants[i]);
TERM *stack[10], **sp = stack, *par;
int parno = 0;
const int stackSize = sizeof(stack) / sizeof(stack[0]); // Calculate the size of the stack array
// find the left-most term and keep params in the stack
while(t->type == TM_APPL) {
if (parno >= stackSize) {
fprintf(stderr, "Error: Stack overflow in execSystemCmd - too many parameters.\n");
// Handle the error, e.g., by safely exiting the function or taking corrective action
return -1; // Return an error code or handle as appropriate for your application
}
*sp++ = t->rterm;
parno++;
t = t->lterm;
}
// The rest of the function...
}- Calculate Stack Size: The stackSize variable is calculated to determine the number of elements in the stack array. This is done by dividing the total size of the array by the size of one element.
- Bounds Check: Before incrementing sp and writing a new parameter to the stack, the code checks if parno is equal to or greater than stackSize. If this condition is true, it means adding another parameter would overflow the stack, so an error is logged, and the function returns early to prevent the overflow.
- Error Handling: In the case of an overflow, an error message is printed, and the function returns a negative value to indicate an error. You should adjust this behavior based on how your application can best handle such errors.
CVE-2024-27542
An invalid pointer dereference vulnerability has been discovered in void termRemoveOper(TERM *t) at termproc.c, line 632. This vulnerability is triggered when processing certain input that leads to an unexpected code path, attempting to dereference an invalid pointer, resulting in a segmentation fault and program crash.
switch(t->type) {Triggering the Vulnerability
To trigger the vulnerability, I’ve provided a proof of concept input that you can feed into LCI named invalid_deref_termRemoverOper. We can send the contents of this text file into lci to view the crash:
$ cat invalid_deref_termRemoverOper | lciAddress Sanitizer Output
ASan catches the crash and provides some helpful information about where in the code this takes place:
=================================================================
==460303==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000018 (pc 0x560e050aa5fa bp 0x7f67bb00bba0 sp 0x7ffdb726f830 T0)
==460303==The signal is caused by a READ memory access.
==460303==Hint: address points to the zero page.
#0 0x560e050aa5fa in termRemoveOper /dev/shm/lci/src/termproc.c:632
#1 0x560e050a5c9b in execTerm /dev/shm/lci/src/run.c:97
#2 0x560e050aa90b in d_final_reduction_code_5_8_gram /dev/shm/lci/src/grammar.g:34
#3 0x560e050c2eb9 in commit_tree /dev/shm/lci/dparser/parse.c:1617
#4 0x560e050c281a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#5 0x560e050c970d in dparse /dev/shm/lci/dparser/parse.c:2121
#6 0x560e050a364b in parse_string /dev/shm/lci/src/parser.c:35
#7 0x560e0509cc9a in main /dev/shm/lci/src/main.c:105
#8 0x7f67bce456c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#9 0x7f67bce45784 in __libc_start_main_impl ../csu/libc-start.c:360
#10 0x560e0509d260 in _start (/dev/shm/lci/build/lci+0x3b260) (BuildId: ff37cd476b852db6d5e5bad433ac32fa2ca6f5de)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /dev/shm/lci/src/termproc.c:632 in termRemoveOper
==460303==ABORTINGFrom the output we can verify that an invalid pointer with the value 0x000000000018 is being dereferenced at termproc.c, line 632.
Mitigation
I’ve provided an immediate workaround example to mitigate the vulnerability until a more comprehensive patch is released. This will apply input validation and sanitization measures to reject potentially malicious or malformed inputs before processing them with LCI. Implementing additional checks for a pointer like 0x000000000018 is challenging, because what constitutes a “valid” pointer can vary. However, for critical software components, you might consider adding comprehensive checks where you suspect pointer corruption:
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h> // For using 'bool' type
// Function to check pointer validity
bool isValidPointer(void* ptr) {
const uintptr_t LOW_MEMORY_THRESHOLD = 0x1000; // Safe threshold for valid memory
return (ptr != NULL) && ((uintptr_t)ptr >= LOW_MEMORY_THRESHOLD);
}
if (isValidPointer(t)) {
switch(t->type) {
case(TM_VAR):
case(TM_ALIAS):
// Handle TM_VAR and TM_ALIAS cases as before
break;
// Other cases as necessary
}
} else {
// Handle the case where 't' is not a valid pointer
fprintf(stderr, "Error: 't' is an invalid pointer.\n");
// Take appropriate action, which might involve returning from the function
// if this code is part of a function that can handle this error scenario.
return; // Or return a specific value/error code if required
}CVE-2024-27540
An invalid pointer dereference vulnerability has been discovered in static TERM fix_precedence(TERM op) at parser.c, line 95. This vulnerability is triggered when processing certain input that leads to an unexpected code path, attempting to dereference an invalid pointer, resulting in a segmentation fault and program crash.
static TERM *fix_precedence(TERM* op) {
TERM *left = op->lterm;
if(left->type != TM_APPL || left->closed) // "closed" means it is protected by parenthesis
return op;Triggering the Vulnerability
To trigger the vulnerability, I’ve provided a proof of concept input that you can feed into LCI named invalid_deref_fix_precedence. We can send the contents of this text file into lci to view the crash:
$ cat invalid_deref_fix_precedence | lciAddress Sanitizer Output
ASan catches the crash and provides some helpful information about where in the code this takes place:
=================================================================
==481033==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000018 (pc 0x55924056894f bp 0x000000000000 sp 0x7fff26e12790 T0)
==481033==The signal is caused by a READ memory access.
==481033==Hint: address points to the zero page.
#0 0x55924056894f in fix_precedence /dev/shm/lci/src/parser.c:95
#1 0x55924056894f in create_application /dev/shm/lci/src/parser.c:139
#2 0x559240570024 in d_final_reduction_code_7_20_gram /dev/shm/lci/src/grammar.g:49
#3 0x559240587eb9 in commit_tree /dev/shm/lci/dparser/parse.c:1617
#4 0x55924058781a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#5 0x55924058781a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#6 0x55924058e70d in dparse /dev/shm/lci/dparser/parse.c:2121
#7 0x55924056864b in parse_string /dev/shm/lci/src/parser.c:35
#8 0x559240561c9a in main /dev/shm/lci/src/main.c:105
#9 0x7f0db9e456c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#10 0x7f0db9e45784 in __libc_start_main_impl ../csu/libc-start.c:360
#11 0x559240562260 in _start (/dev/shm/lci/build/lci+0x3b260) (BuildId: ff37cd476b852db6d5e5bad433ac32fa2ca6f5de)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /dev/shm/lci/src/parser.c:95 in fix_precedence
==481033==ABORTINGFrom the output we can verify that an invalid pointer with the value 0x000000000018 is being dereferenced at parser.c, line 95.
Mitigation
I’ve provided an immediate workaround example to mitigate the vulnerability until a more comprehensive patch is released. This will apply input validation and sanitization measures to reject potentially malicious or malformed inputs before processing them with LCI. Like before, implementing additional checks for a pointer like 0x000000000018 is challenging, because what constitutes a “valid” pointer can vary. However, for critical software components, you might consider adding comprehensive checks where you suspect pointer corruption:
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h> // For using 'bool' type
// Function to check pointer validity
bool isValidPointer(void* ptr) {
const uintptr_t LOW_MEMORY_THRESHOLD = 0x1000;
return (ptr != NULL) && ((uintptr_t)ptr >= LOW_MEMORY_THRESHOLD);
}
static TERM *fix_precedence(TERM* op) {
// Ensure 'op' is not a null or invalid pointer
if (!isValidPointer(op)) {
fprintf(stderr, "Error: Invalid 'op' pointer in fix_precedence.\n");
return NULL;
}
TERM *left = op->lterm;
// Ensure 'left' is not a null or invalid pointer before dereferencing
if (isValidPointer(left)) {
if(left->type != TM_APPL || left->closed) {
return op;
}
// Additional logic to handle 'left'...
} else {
fprintf(stderr, "Error: Invalid 'left' pointer in fix_precedence.\n");
// Handle invalid 'left' pointer scenario
// Depending on the context, you might return 'op', NULL, or take other actions
return op; // Example action
}
// Rest of the function...
}CVE-2024-27541
An invalid pointer dereference vulnerability has been discovered in TERM* create_bracket(TERM *t) at parser.c, line 162. This vulnerability is triggered when processing certain input that leads to an unexpected code path, attempting to dereference an invalid pointer, resulting in a segmentation fault and program crash.
TERM* create_bracket(TERM *t) {
t->closed = 1; // during parsing, 'closed' means enclosed in brackets
return t;
} Triggering the Vulnerability
To trigger the vulnerability, I’ve provided a proof of concept input that you can feed into LCI named invalid_deref_create_bracket. We can send the contents of this text file into lci to view the crash:
$ cat invalid_deref_create_bracket | lciAddress Sanitizer Output
ASan catches the crash and provides some helpful information about where in the code this takes place:
=================================================================
==502918==ERROR: AddressSanitizer: SEGV on unknown address 0x00000000001c (pc 0x556f680df0d3 bp 0x7ffee67786b0 sp 0x7ffee6778668 T0)
==502918==The signal is caused by a WRITE memory access.
==502918==Hint: address points to the zero page.
#0 0x556f680df0d3 in create_bracket /dev/shm/lci/src/parser.c:162
#1 0x556f680e5aaf in d_final_reduction_code_7_14_gram /dev/shm/lci/src/grammar.g:40
#2 0x556f680fdeb9 in commit_tree /dev/shm/lci/dparser/parse.c:1617
#3 0x556f680fd81a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#4 0x556f680fd81a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#5 0x556f680fd81a in commit_tree /dev/shm/lci/dparser/parse.c:1602
#6 0x556f6810470d in dparse /dev/shm/lci/dparser/parse.c:2121
#7 0x556f680de64b in parse_string /dev/shm/lci/src/parser.c:35
#8 0x556f680d7c9a in main /dev/shm/lci/src/main.c:105
#9 0x7fb7478456c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#10 0x7fb747845784 in __libc_start_main_impl ../csu/libc-start.c:360
#11 0x556f680d8260 in _start (/dev/shm/lci/build/lci+0x3b260) (BuildId: ff37cd476b852db6d5e5bad433ac32fa2ca6f5de)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /dev/shm/lci/src/parser.c:162 in create_bracket
==502918==ABORTINGThe ASan output indicates a segmentation fault caused by a write memory access to an invalid address (0x00000000001c), occurring in the create_bracket function. This issue arises when attempting to set the closed field of a TERM structure through a pointer that may be invalid or uninitialized.
Mitigation
I’ve provided an immediate workaround example to mitigate the vulnerability until a more comprehensive patch is released. This will apply input validation and sanitization measures to reject potentially malicious or malformed inputs before processing them with LCI:
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
bool isValidPointer(void* ptr) {
const uintptr_t LOW_MEMORY_THRESHOLD = 0x1000;
return (ptr != NULL) && ((uintptr_t)ptr >= LOW_MEMORY_THRESHOLD);
}Updated create_bracket function:
TERM* create_bracket(TERM *t) {
// Check if 't' is a valid pointer before dereferencing
if (!isValidPointer(t)) {
fprintf(stderr, "Error: Invalid 't' pointer in create_bracket.\n");
return NULL; // Or handle the error as appropriate for your application
}
t->closed = 1; // during parsing, 'closed' means enclosed in brackets
return t;
}Overview of Impact
The stack buffer overflow vulnerability in the execSystemCmd function poses the most critical risk, potentially leading to arbitrary code execution. In scenarios where LCI is used in a web environment or is accessible by untrusted users, an attacker could craft specific inputs to overflow the stack buffer, manipulate the execution flow, and execute malicious code. This could result in the compromise of the hosting system, allowing the attacker to gain unauthorized access, escalate privileges, or launch further attacks from the compromised system. For programs built on top of LCI, this vulnerability exposes them to a chain of threats where an exploit against LCI could lead to the compromise of the entire application stack, affecting not just the LCI runtime but also any application logic, data, or services relying on it.
The three instances of invalid pointer dereference in termRemoveOper, fix_precedence, and create_bracket functions primarily lead to denial of service (DoS) through program crashes. However, the impact could extend beyond a simple service disruption in specific environments or use cases:
- Information Disclosure: In certain configurations, the crash details (e.g., core dumps) might expose sensitive runtime information to attackers, aiding them in crafting further exploits. For applications built on LCI, such information disclosure could inadvertently reveal application logic, data structures, or even sensitive user data being processed at the time of the crash, leading to a broader security breach.
- Remote Code Execution (RCE): Although less likely than with the stack buffer overflow, there exists a theoretical possibility for remote code execution if the attacker can control the memory layout or exploit specific behaviors of the memory management in the hosting environment. Applications utilizing LCI as a foundation for processing or execution logic are particularly at risk, as any RCE vulnerability in LCI can be escalated to execute arbitrary code within the context of the host application, potentially allowing attackers to manipulate application behavior, access sensitive information, or exploit further vulnerabilities in the application stack.
- Extended Implications for Programs Built on LCI: The inherent risks of these vulnerabilities are magnified for programs built on LCI due to the cascading nature of security breaches. An exploit at the language interpreter level can provide an attacker with a foothold into higher levels of the application stack, from where they can mount attacks against other components of the system. This is especially critical for systems where LCI is used to process untrusted input or in environments where LCI’s output directly influences other application components or user-facing features.
Conclusion
In conclusion, the Lambda Calculus Interpreter (LCI) exemplifies the critical intersection of theoretical computer science with practical application, underscoring the essential nature of functional programming in modern computation. However, our journey through the intricacies of LCI, its vulnerabilities uncovered through rigorous fuzzing with AFL++, and the subsequent mitigation strategies highlight a fundamental truth in software development: security is paramount. The vulnerabilities identified, ranging from stack buffer overflows to invalid pointer dereferences, not only reveal the potential risks inherent in software development but also serve as a clarion call for the integration of robust security practices throughout the software lifecycle.
The use of AFL++ in our analysis demonstrates the power of advanced fuzzing tools in identifying and mitigating security risks, providing a pathway for developers and researchers to secure their applications against increasingly sophisticated attacks. It’s a reminder that in the realm of software development, vigilance, and proactive security measures are not just best practices but necessities.
As we move forward, the lessons learned from fuzzing LCI with AFL++ should inspire a broader appreciation for the role of formal methods and security testing in software development. By embracing these tools and techniques, we can ensure that our digital infrastructure remains robust, reliable, and resilient against the challenges of the future. Let the exploration of LCI and its vulnerabilities serve as a testament to the ongoing dialogue between theory and practice in computer science, a dialogue that continues to shape the evolution of technology in our interconnected world.
No responses yet