
Ever felt the frustration of trying to find that one moment in a video without having to scrub through hours of footage? Well, you’re in good company. As someone who spends a significant amount of time working with digital media, I often wished for a magic tool that could instantly locate specific content within my media library. That wish led me to create a text-to-video search tool using Jupyter Notebook, leveraging some cutting-edge technologies.
In this blog post, I’ll walk you through the journey of building this powerful tool, from setting up the environment and processing videos to storing and querying embeddings. Whether you’re a developer, a video editor, or simply a tech enthusiast, I hope you find this exploration as exciting and insightful as I did.
Prerequisite Knowledge
- Langchain -> https://python.langchain.com/docs/tutorials/
- Milvus -> https://milvus.io/docs/quickstart.md
- Ollama -> https://ollama.com/
- Python3/Jupyter Notebooks -> https://docs.python.org/3/tutorial/index.html
- Vector Embeddings -> https://milvus.io/intro
- Multimodal Models -> https://ollama.com/library/llava
Architecture Overview
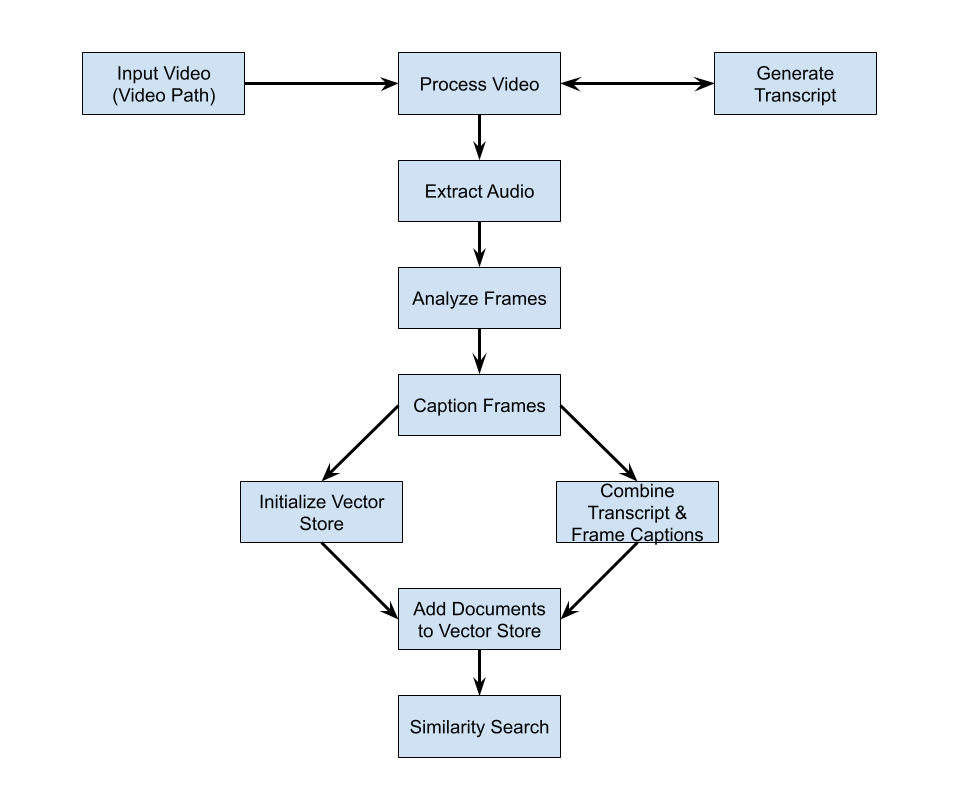
Ollama Setup
To kick off this text-to-video search project, you’ll first need to set up Ollama on your local system. Begin by downloading and installing Ollama from the official website, which supports MacOS, Windows, and Linux. Once the installation is complete, make sure to pull the two crucial models: the LLaVA model for image captioning and the nomic-embed-text model for generating embeddings.
ollama pull llavaollama pull nomic-embed-textThe LLaVA model is specifically designed for vision-related tasks and comes in different sizes. Additionally, you’ll need to ensure Ollama is running as a server, which typically operates on port 11434 by default.
Install FFMPEG
OpenAI Whisper is used for automatic speech recognition (ASR) tasks, enabling it to transcribe spoken language into text accurately. It’s designed to handle a wide range of accents and languages, making it a versatile tool for applications like transcription services, voice commands, and language learning aids.
Whisper requires ffmpeg as a mandatory dependency. FFmpeg is a command-line tool that helps Whisper handle various audio formats by converting them into readable formats.
Installation Methods
You can install ffmpeg using package managers depending on your operating system:
Linux (Ubuntu/Debian)
sudo apt update && sudo apt install ffmpegMacOS
brew install ffmpegWindows
choco install ffmpegImportant Notes
- FFmpeg must be installed before using Whisper. Without it, you’ll encounter errors when trying to process audio.
- The ffmpeg installation command for MacOS requires Homebrew, and Windows requires Chocolatey.
- After installing ffmpeg, you may need to restart your development environment or terminal for the changes to take effect.
Install Python Dependencies
%pip install -U langchain langchain-community langchain_milvus langchain-ollama ollama moviepy==2.0.0.dev2 pillow numpy opencv-pythonThe code above is a Jupyter notebook magic command that installs or upgrades several Python packages using pip. The packages being installed or upgraded are:
langchain: A framework for developing AI applications powered by language models.langchain-community: Community-contributed components for LangChain.langchain_milvus: LangChain integration with Milvus, a vector database.langchain-ollama: LangChain integration with Ollama.ollama: A tool for running large language models locally.moviepy==2.0.0.dev2: A library for video editing with Python (specifying a development version).pillow: A library for opening, manipulating, and saving image files.numpy: A library for numerical computing in Python.opencv-python: OpenCV library for computer vision tasks.
Import Required Libraries
The next code block contains import statements that load the various libraries and modules necessary for the functionality of the tool. Let’s break down each import:
import tempfile
from moviepy.video.io.VideoFileClip import VideoFileClip
import whisper
import ollama
from langchain_ollama import OllamaEmbeddings
from langchain_milvus import Milvus
import numpy as np
import cv2
import base64
from io import BytesIO
from PIL import Image
from langchain.schema import Document
import osimport tempfile: This module is used for creating temporary files and directories when handling temporary audio files during video processing.from moviepy.video.io.VideoFileClip import VideoFileClip: This imports the VideoFileClip class from the moviepy library, which is used for video editing and manipulation.import whisper: This imports the Whisper library, which is an automatic speech recognition system developed by OpenAI. It’s used for transcribing audio from videos.import ollama: Ollama is a library for running large language models locally. It’s used here for captioning images.from langchain_ollama import OllamaEmbeddings: This imports the OllamaEmbeddings class from the langchain_ollama module, which is used for generating embeddings for text using Ollama models.from langchain_milvus import Milvus: This imports the Milvus class from langchain_milvus, which is used for interacting with the Milvus vector database.import numpy as np: NumPy is imported for numerical operations, like handling video frames as arrays.import cv2: OpenCV is imported, which is a computer vision library used for image processing tasks.import base64: This module provides functions for encoding and decoding data using base64 encoding.from io import BytesIO: BytesIO is imported to handle byte streams in memory.from PIL import Image: The Python Imaging Library (PIL) is imported for image processing tasks.from langchain.schema import Document: This imports the Document class from langchain, which is used to represent text documents with metadata.import os: The os module is imported for interacting with the operating system using file path operations.
Base64 Conversion Function
The following function takes a video frame (typically a numpy array) and converts it to a base64-encoded string representation of a JPEG image.
def frame_to_base64(frame):
# Convert numpy array to PIL Image
image = Image.fromarray(frame)
# Convert to RGB if necessary
if image.mode != 'RGB':
image = image.convert('RGB')
# Save to bytes
buffered = BytesIO()
image.save(buffered, format="JPEG")
# Encode to base64
img_str = base64.b64encode(buffered.getvalue()).decode()
return img_strHere’s a breakdown of what each part does:
image = Image.fromarray(frame)Converts the numpy array (frame) to a PIL (Python Imaging Library) Image object.
if image.mode != 'RGB':
image = image.convert('RGB'): Ensures the image is in RGB mode. If it’s not, it converts it to RGB. This is important because some image processing operations expect RGB images.
buffered = BytesIO()Creates a binary stream in memory to temporarily hold the image data.
image.save(buffered, format="JPEG")Saves the image to the in-memory buffer in JPEG format.
img_str = base64.b64encode(buffered.getvalue()).decode()The contents of the buffer are encoded into a Base64 string. The b64encode method from the base64 module does the encoding, and the resulting bytes are decoded into a string.
return img_strReturns the base64-encoded string representation of the image.
Process Videos
The next function takes a video file and converts it into searchable documents by combining audio transcription with visual descriptions.
def process_video(video_path):
try:
video = VideoFileClip(video_path)
if not video.audio:
print("Warning: Video has no audio track. Proceeding with visual frame captions only.")
except FileNotFoundError:
print(f"Error: The file {video_path} was not found.")
return
except Exception as e:
print(f"An error occurred while loading video: {e}")
return
audio_transcriptions = []
if video.audio:
try:
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as temp_audio:
video.audio.write_audiofile(temp_audio.name, logger=None)
audio_path = temp_audio.name
try:
whisper_model = whisper.load_model("base")
result = whisper_model.transcribe(audio_path)
audio_transcriptions = result['segments']
except Exception as e:
print(f"An error occurred during transcription: {e}")
except Exception as e:
print(f"An error occurred while extracting audio: {e}")
else:
print("No audio transcriptions will be processed.")
frames = []
try:
for t in range(0, int(video.duration), 5):
frame = video.get_frame(t)
# Convert frame to uint8 format
frame = (frame * 255).astype(np.uint8)
# Convert frame to base64
frame_base64 = frame_to_base64(frame)
response = ollama.chat(
model="llava",
messages=[{
'role': 'user',
'content': 'Describe this frame.',
'images': [frame_base64]
}]
)
frames.append({
'timestamp': t,
'description': response['message']['content']
})
except Exception as e:
print(f"An error occurred while processing frames: {e}")
finally:
video.close()
combined_documents = []
for t in range(0, int(video.duration), 5):
content = ""
# Find the matching audio transcription for the current timestamp
matching_segments = [segment for segment in audio_transcriptions if abs(segment['start'] - t) < 5]
if matching_segments:
segment = matching_segments[0]
content += f"Transcript: {segment['text']}\n"
content += f"Visual: {' '.join(f['description'] for f in frames if abs(f['timestamp'] - segment['start']) < 5)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': segment['start'], 'filename': os.path.basename(video_path), 'duration': segment['end'] - segment['start']}
))
else:
matching_frames = [f for f in frames if abs(f['timestamp'] - t) < 5]
content += f"Visual: {' '.join(f['description'] for f in matching_frames)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': t, 'filename': os.path.basename(video_path), 'duration': 5}
))
return combined_documents
Loading the Video File
The function begins by attempting to load the video file specified by video_path. It checks whether the video has an audio track:
try:
video = VideoFileClip(video_path)
if not video.audio:
print("Warning: Video has no audio track. Proceeding with visual frame captions only.")
except FileNotFoundError:
print(f"Error: The file {video_path} was not found.")
return
except Exception as e:
print(f"An error occurred while loading video: {e}")
return
If the video has no audio, it prints a warning but continues processing. If the file isn’t found or another error occurs while loading, it prints an error message and stops.
Handling Audio Transcription
If the video has an audio track, the function extracts the audio and transcribes it:
audio_transcriptions = []
if video.audio:
try:
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as temp_audio:
video.audio.write_audiofile(temp_audio.name, logger=None)
audio_path = temp_audio.name
try:
whisper_model = whisper.load_model("base")
result = whisper_model.transcribe(audio_path)
audio_transcriptions = result['segments']
except Exception as e:
print(f"An error occurred during transcription: {e}")
except Exception as e:
print(f"An error occurred while extracting audio: {e}")
else:
print("No audio transcriptions will be processed.")
The function writes the audio track to a temporary MP3 file and uses Whisper to transcribe the audio, storing the transcriptions in audio_transcriptions. If an error occurs, it prints an error message.
Processing Video Frames
Next, the function iterates through the video, extracting frames every 5 seconds. Each frame is converted to Base64 and sent to the ollama API, which returns a detailed image description (caption). These descriptions are stored in a list with their timestamps.
frames = []
try:
for t in range(0, int(video.duration), 5):
frame = video.get_frame(t)
# Convert frame to uint8 format
frame = (frame * 255).astype(np.uint8)
# Convert frame to base64
frame_base64 = frame_to_base64(frame)
response = ollama.chat(
model="llava",
messages=[{
'role': 'user',
'content': 'Describe this frame.',
'images': [frame_base64]
}]
)
frames.append({
'timestamp': t,
'description': response['message']['content']
})
except Exception as e:
print(f"An error occurred while processing frames: {e}")
finally:
video.close()
Combining Audio and Visual Data
Finally, the function combines audio transcriptions with corresponding visual frame descriptions:
combined_documents = []
for t in range(0, int(video.duration), 5):
content = ""
# Find the matching audio transcription for the current timestamp
matching_segments = [segment for segment in audio_transcriptions if abs(segment['start'] - t) < 5]
if matching_segments:
segment = matching_segments[0]
content += f"Transcript: {segment['text']}\n"
content += f"Visual: {' '.join(f['description'] for f in frames if abs(f['timestamp'] - segment['start']) < 5)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': segment['start'], 'filename': os.path.basename(video_path), 'duration': segment['end'] - segment['start']}
))
else:
matching_frames = [f for f in frames if abs(f['timestamp'] - t) < 5]
content += f"Visual: {' '.join(f['description'] for f in matching_frames)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': t, 'filename': os.path.basename(video_path), 'duration': 5}
))
return combined_documents
It pairs audio transcriptions with visual descriptions where timestamps match within a 5-second window. For frames without audio, it ensures visual descriptions are still included. Each combined document contains both transcript and visual descriptions with metadata.
Initialize Vector Store
This following function, initialize_vector_store, is responsible for setting up the vector database which will be used to store and query embeddings.
def initialize_vector_store():
try:
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"uri": "./video-search.db"},
auto_id=True,
)
return vector_store
except Exception as e:
print(f"Error initializing vector store: {e}")
return Nonedef initialize_vector_store():- The function
initialize_vector_storeis defined without any parameters.
- The function
try:- The function starts a
tryblock to catch any potential exceptions that might occur during the initialization process.
- The function starts a
embeddings = OllamaEmbeddings(model="nomic-embed-text")- This line initializes an
OllamaEmbeddingsobject with thenomic-embed-textmodel. This object is used to generate embeddings for the text data.
- This line initializes an
vector_store = Milvus( embedding_function=embeddings, connection_args={"uri": "./video-search.db"}, auto_id=True, )- This line initializes a
Milvusvector store. - Specifies the embedding function to use, which is the
OllamaEmbeddingsobject initialized earlier. - Provides the connection arguments for Milvus, indicating the URI of the database file
video-search.db. - Automatically assigns IDs to the stored documents with
auto_id=True.
- This line initializes a
return vector_store- If no exceptions occur, the function returns the initialized
vector_storeobject.
- If no exceptions occur, the function returns the initialized
except Exception as e: print(f"Error initializing vector store: {e}") return None- If an exception occurs during the process, it is caught and an error message is printed.
- The function returns
Noneto indicate that the initialization failed.
Main Function
The main function orchestrates the overall process of the video-to-text-to-embedding pipeline. It begins by initializing the vector store using the initialize_vector_store function. If the vector store initialization fails, the function exits early. If the vector store initialization was successful, it processes the given video file with the process_video function to generate transcribed and described video documents.
def main(video_path):
vector_store = initialize_vector_store()
if not vector_store:
return
video_documents = process_video(video_path)
if video_documents:
try:
vector_store.add_documents(video_documents)
print("Successfully processed video and stored embeddings")
except Exception as e:
print(f"Error storing documents in vector store: {e}")If the video documents are successfully created, the function attempts to add these documents to the vector store, printing a success message if the operation is successful. If any errors occur during this process, they are caught, and an error message is printed. This function essentially integrates all the key components of the project, ensuring smooth execution and error handling.
Using the Tool
The next lines of code call the main function twice with different video file paths, "news.mp4" and "condo-tour.mp4". Each call initiates the entire processing pipeline for the specified video file. This means it will:
- Initialize the vector store.
- Process the video file to extract audio, transcribe the audio, and generate descriptions for video frames.
- Combine the transcriptions and descriptions into documents.
- Add these documents to the vector store.
main("news.mp4")
main("condo-tour.mp4")Essentially, running these lines will process and store the embeddings for both news.mp4 and condo-tour.mp4 videos in the vector store. To utilize this tool effectively, follow these steps:
- Download Video Files: Download the video files you wish to process. These files can be any videos that you want to include in the search tool.
- Place in Correct Directory: Place these video files in the directory where your Jupyter Notebook is located or specify the correct file path in the
video_pathparameter. This ensures that theprocess_videofunction can locate and access the video files. - Replace File Names: Replace the video file names in the function calls with the names of your actual video files. For example, if your video files are named
my_video1.mp4andmy_video2.mp4, you should call themainfunction as follows:
main("my_video1.mp4")
main("my_video2.mp4")Semantic Video Search
The final section shows the similarity scores and detailed content of the most relevant video segments for any given query. This allows users to quickly locate specific parts of their video library based on text queries.
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"uri": "./video-search.db"},
auto_id=True,
)
# Search with similarity scores
results = vector_store.similarity_search_with_score(
"Inside",
k=5
)
for doc, score in results:
print(f"Similarity Score: {score:.3f}")
print(f"---Content---\n")
print(f"Filename: {doc.metadata['filename']}")
print(f"Duration: {doc.metadata['duration']} seconds")
print(f"Timestamp: {doc.metadata['timestamp']} seconds")
print(f"{doc.page_content}")
print("-------------------")
This section of the code performs the following tasks:
- Initialize Embeddings and Vector Store:
- Initializes an
OllamaEmbeddingsobject with thenomic-embed-textmodel, which will be used to generate text embeddings. - Initializes a
Milvusvector store to handle the storage and retrieval of these embeddings. The connection arguments specify the location of the database file (video-search.db).
- Initializes an
- Perform a Similarity Search:
- Executes a similarity search in the vector store using the query
"Inside". - Retrieves the top 5 results (
k=5) that are most similar to the query, along with their similarity scores.
- Executes a similarity search in the vector store using the query
- Print Search Results:
- Iterate over the search results and print the similarity score for each document.
- Displays metadata such as the filename, duration, and timestamp, as well as the document’s content.

Conclusion
This project showcases how powerful AI tools can come together to solve everyday problems, like quickly finding specific moments in long videos. Whether for personal use or larger projects, this tool highlights the transformative potential of AI in video data management.
Happy Coding!
Full Code
import tempfile
from moviepy.video.io.VideoFileClip import VideoFileClip
import whisper
import ollama
from langchain_ollama import OllamaEmbeddings
from langchain_milvus import Milvus
import numpy as np
import cv2
import base64
from io import BytesIO
from PIL import Image
from langchain.schema import Document
import os
def frame_to_base64(frame):
# Convert numpy array to PIL Image
image = Image.fromarray(frame)
# Convert to RGB if necessary
if image.mode != 'RGB':
image = image.convert('RGB')
# Save to bytes
buffered = BytesIO()
image.save(buffered, format="JPEG")
# Encode to base64
img_str = base64.b64encode(buffered.getvalue()).decode()
return img_str
def process_video(video_path):
try:
video = VideoFileClip(video_path)
if not video.audio:
print("Warning: Video has no audio track. Proceeding with visual frame captions only.")
except FileNotFoundError:
print(f"Error: The file {video_path} was not found.")
return
except Exception as e:
print(f"An error occurred while loading video: {e}")
return
audio_transcriptions = []
if video.audio:
try:
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as temp_audio:
video.audio.write_audiofile(temp_audio.name, logger=None)
audio_path = temp_audio.name
try:
whisper_model = whisper.load_model("base")
result = whisper_model.transcribe(audio_path)
audio_transcriptions = result['segments']
except Exception as e:
print(f"An error occurred during transcription: {e}")
except Exception as e:
print(f"An error occurred while extracting audio: {e}")
else:
print("No audio transcriptions will be processed.")
frames = []
try:
for t in range(0, int(video.duration), 5):
frame = video.get_frame(t)
# Convert frame to uint8 format
frame = (frame * 255).astype(np.uint8)
# Convert frame to base64
frame_base64 = frame_to_base64(frame)
response = ollama.chat(
model="llava",
messages=[{
'role': 'user',
'content': 'Describe this frame.',
'images': [frame_base64]
}]
)
frames.append({
'timestamp': t,
'description': response['message']['content']
})
except Exception as e:
print(f"An error occurred while processing frames: {e}")
finally:
video.close()
combined_documents = []
for t in range(0, int(video.duration), 5):
content = ""
# Find the matching audio transcription for the current timestamp
matching_segments = [segment for segment in audio_transcriptions if abs(segment['start'] - t) < 5]
if matching_segments:
segment = matching_segments[0]
content += f"Transcript: {segment['text']}\n"
content += f"Visual: {' '.join(f['description'] for f in frames if abs(f['timestamp'] - segment['start']) < 5)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': segment['start'], 'filename': os.path.basename(video_path), 'duration': segment['end'] - segment['start']}
))
else:
matching_frames = [f for f in frames if abs(f['timestamp'] - t) < 5]
content += f"Visual: {' '.join(f['description'] for f in matching_frames)}"
combined_documents.append(Document(
page_content=content,
metadata={'timestamp': t, 'filename': os.path.basename(video_path), 'duration': 5}
))
return combined_documents
def initialize_vector_store():
try:
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"uri": "./video-search.db"},
auto_id=True,
)
return vector_store
except Exception as e:
print(f"Error initializing vector store: {e}")
return None
def main(video_path):
vector_store = initialize_vector_store()
if not vector_store:
return
video_documents = process_video(video_path)
if video_documents:
try:
vector_store.add_documents(video_documents)
print("Successfully processed video and stored embeddings")
except Exception as e:
print(f"Error storing documents in vector store: {e}")
main("news.mp4")
main("condo-tour.mp4")
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"uri": "./video-search.db"},
auto_id=True,
)
# Search with similarity scores
results = vector_store.similarity_search_with_score(
"Window",
k=5
)
for doc, score in results:
print(f"Similarity Score: {score:.3f}")
print(f"---Content---\n")
print(f"Filename: {doc.metadata['filename']}")
print(f"Duration: {doc.metadata['duration']} seconds")
print(f"Timestamp: {doc.metadata['timestamp']} seconds")
print(f"{doc.page_content}")
print("-------------------")
Full Code Without Langchain
import tempfile
from moviepy.video.io.VideoFileClip import VideoFileClip
import whisper
import ollama
from pymilvus import MilvusClient
import numpy as np
import cv2
import base64
from io import BytesIO
from PIL import Image
import os
from typing import List, Dict
def frame_to_base64(frame):
# Convert numpy array to PIL Image
image = Image.fromarray(frame)
# Convert to RGB if necessary
if image.mode != 'RGB':
image = image.convert('RGB')
# Save to bytes
buffered = BytesIO()
image.save(buffered, format="JPEG")
# Encode to base64
img_str = base64.b64encode(buffered.getvalue()).decode()
return img_str
def process_video(video_path: str) -> List[Dict]:
try:
video = VideoFileClip(video_path)
if not video.audio:
print("Warning: Video has no audio track. Proceeding with visual frame captions only.")
except FileNotFoundError:
print(f"Error: The file {video_path} was not found.")
return []
except Exception as e:
print(f"An error occurred while loading video: {e}")
return []
audio_transcriptions = []
if video.audio:
try:
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as temp_audio:
video.audio.write_audiofile(temp_audio.name, logger=None)
audio_path = temp_audio.name
try:
whisper_model = whisper.load_model("base")
result = whisper_model.transcribe(audio_path)
audio_transcriptions = result['segments']
except Exception as e:
print(f"An error occurred during transcription: {e}")
except Exception as e:
print(f"An error occurred while extracting audio: {e}")
else:
print("No audio transcriptions will be processed.")
frames = []
try:
for t in range(0, int(video.duration), 5):
frame = video.get_frame(t)
# Convert frame to uint8 format
frame = (frame * 255).astype(np.uint8)
# Convert frame to base64
frame_base64 = frame_to_base64(frame)
response = ollama.chat(
model="llava",
messages=[{
'role': 'user',
'content': 'Describe this frame.',
'images': [frame_base64]
}]
)
frames.append({
'timestamp': t,
'description': response['message']['content']
})
except Exception as e:
print(f"An error occurred while processing frames: {e}")
finally:
video.close()
combined_documents = []
for t in range(0, int(video.duration), 5):
content = ""
# Find the matching audio transcription for the current timestamp
matching_segments = [segment for segment in audio_transcriptions if abs(segment['start'] - t) < 5]
if matching_segments:
segment = matching_segments[0]
content += f"Transcript: {segment['text']}\n"
content += f"Visual: {' '.join(f['description'] for f in frames if abs(f['timestamp'] - segment['start']) < 5)}"
combined_documents.append({
'content': content,
'metadata': {
'timestamp': segment['start'],
'filename': os.path.basename(video_path),
'duration': segment['end'] - segment['start']
}
})
else:
matching_frames = [f for f in frames if abs(f['timestamp'] - t) < 5]
content += f"Visual: {' '.join(f['description'] for f in matching_frames)}"
combined_documents.append({
'content': content,
'metadata': {
'timestamp': t,
'filename': os.path.basename(video_path),
'duration': 5
}
})
return combined_documents
def initialize_vector_store():
try:
milvus_client = MilvusClient(uri="./no-lang-video-search.db")
collection_name = "video_collection"
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
milvus_client.create_collection(
collection_name=collection_name,
dimension=768,
metric_type="IP",
consistency_level="Strong",
auto_id=True
)
return milvus_client
except Exception as e:
print(f"Error initializing vector store: {e}")
return None
def add_documents_to_vector_store(milvus_client, documents: List[Dict]):
try:
data = []
for doc in documents:
response = ollama.embeddings(
model='nomic-embed-text',
prompt=doc['content']
)
data.append({
"vector": response['embedding'],
"content": doc['content'],
"timestamp": doc['metadata']['timestamp'],
"filename": doc['metadata']['filename'],
"duration": doc['metadata']['duration']
})
if len(data) > 0:
milvus_client.insert(
collection_name="video_collection",
data=data
)
print("Successfully processed video and stored embeddings")
except Exception as e:
print(f"Error storing documents in vector store: {e}")
def search_similar(query: str, k: int = 5):
milvus_client = MilvusClient(uri="./no-lang-video-search.db")
response = ollama.embeddings(
model='nomic-embed-text',
prompt=query
)
query_embedding = response['embedding']
results = milvus_client.search(
collection_name="video_collection",
data=[query_embedding],
limit=k,
search_params={
"metric_type": "IP",
"params": {}
},
output_fields=["content", "timestamp", "filename", "duration"]
)
for hit in results[0]:
print(f"Similarity Score: {hit['distance']:.3f}")
print(f"---Content---\n")
print(f"Filename: {hit['entity']['filename']}")
print(f"Duration: {hit['entity']['duration']} seconds")
print(f"Timestamp: {hit['entity']['timestamp']} seconds")
print(f"{hit['entity']['content']}")
print("-------------------")
def main(video_path: str):
milvus_client = initialize_vector_store()
if milvus_client is None:
return
video_documents = process_video(video_path)
if video_documents:
add_documents_to_vector_store(milvus_client, video_documents)
# Process videos
main("news.mp4")
main("condo-tour.mp4")
# Example search
search_similar("Window", k=5)
No responses yet